

目次
はじめに
コーヒーにこだわりたいけど豆に触れると沼だと思って手を出していません。ゲームエンジン・エンハンスメント学部 中村です。前回の記事ではUnitySentis+ML-Agentsのサンプルに触れたので、今回はもう少し踏み込んでUnitySentisを用いたSpeechToTextを実行しましょう。さらに声をコマンドにしてキャラクターを動かすちょっとしたゲームを作っていきます。
UnitySentis
前回の記事でも触れましたが、Unity Sentisはニューラルネットワークをもとに学習されたonnxファイルをインポートし、そのAIモデルをUnityがサポートするプラットフォームで直接実行することができます。これによって、音声認識や手書き文字認識などがWebを経由することがないので、ネットワークインフラに依存する必要がなくなります。
まずはサンプルから
何事もまずはサンプルから始めていきましょう。
UnitySentisでSpeechToTextを実行するためには、そのAIモデルが必要になります。SpeechToTextといえば、Web上から実行できる OpenAI 製の Whisper が有名なのでそちらを利用しましょう。WhisperはHuggingFaceにオープンソースで公開されており、その構造の詳しい説明書も含まれています。
今回はUnityから公開されているこちらのサンプルを使用していきます。このサンプルに含まれているファイルは以下のとおりです。
- answering-machine16kHz.wav:テキストに変換したい音声ファイル
- LogMelSepctro.sentis:音声波形をlog-melスペクトル変換するモデル
- AudioEncoder_Tiny.sentis:log-melスペクトル変換された音声からその特徴量に変換するモデル
- AudioDecoder_Tiny.sentis:音声特徴量とテキストトークンから次のトークンを予測するモデル
- vocab.json:トークンと文字の組み合わせ
- RunWhisper.cs:UnitySentisを利用してSpeechToTextを実行するコード
このサンプルではReadmeに記述されている通りの手順で実行していきました。
- Unity2023.2.11 で新規プロジェクトを作成し、サンプルファイル群をインポート
- com.unity.sentis パッケージをインポート
- RunWhisper.cs ファイルをMainCameraにアタッチ
- sentisファイルとvocab.jsonをAssets/StreamingAssetsフォルダへ移動
- answering-machine16kHz.wavをインスペクタから “Force Mono” と “Decompress on Load” をONにする
この状態でUnityをPlayすると、以下のようにデバッグログが出力されて音声がテキストに変換されている様子を確認できます。
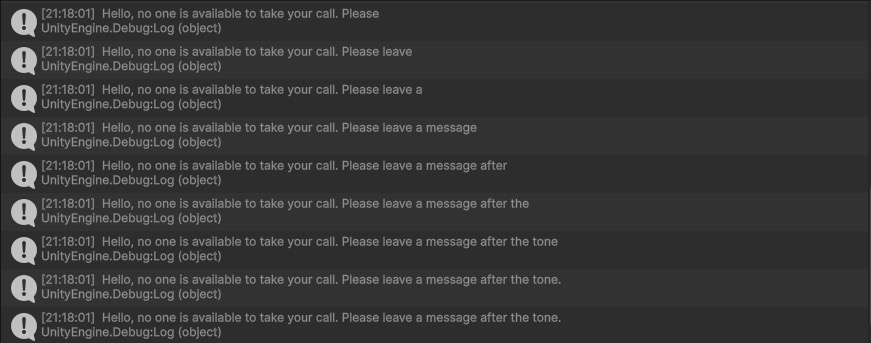
サンプルの中身を理解する
一旦 Unity 上で SpeechToText が動作していることを確認できました。ここで RunWhisper.cs がどのような動きをしているか見ていきます。私の理解でコメントを付けています。
void Start()
{
// 推論に利用するテンソルをキャッシュ,もしくは単にメモリ割り当てを行う仕組み.
allocator = new TensorCachingAllocator();
// テンソル演算を実行するインスタンスを生成する(Opsはオペレーションか?).ここでbackendはSentisの実行環境を示しGPUを指定している.
ops = WorkerFactory.CreateOps(backend, allocator);
// 変換後の特殊文字を白埋めするのでその配列を初期化.
SetupWhiteSpaceShifts();
// vocab.jsonからトークンと文字の割当をロード.
GetTokens();
// StreamingAssetsからモデルファイルを読み込む.
Model decoder = ModelLoader.Load(Application.streamingAssetsPath + "/AudioDecoder_Tiny.sentis");
Model encoder = ModelLoader.Load(Application.streamingAssetsPath + "/AudioEncoder_Tiny.sentis");
Model spectro = ModelLoader.Load(Application.streamingAssetsPath + "/LogMelSepctro.sentis");
// 読み込んだモデルからニューラルネットワークを実行するワーカーのインスタンスを生成する.
decoderEngine = WorkerFactory.CreateWorker(backend, decoder);
encoderEngine = WorkerFactory.CreateWorker(backend, encoder);
spectroEngine = WorkerFactory.CreateWorker(backend, spectro);
// デコーダーに指定する入出力トークンを初期化する.
// index:0 は 単に SpeechToText を開始する合図.
// index:1 は 言語の指定.
// index:2 は 同じ言語の文字列 に変換するか 別の言語に翻訳するか.
// index:3 は 文字起こしにタイムスタンプを利用するか.
outputTokens[0] = START_OF_TRANSCRIPT;
outputTokens[1] = ENGLISH;// GERMAN;//FRENCH;//
outputTokens[2] = TRANSCRIBE; //TRANSLATE;//
outputTokens[3] = NO_TIME_STAMPS;// START_TIME;//
currentToken = 3;
// 音声をロード.
LoadAudio();
// ロードした音声を変換.
EncodeAudio();
transcribe = true;
}まずRunWhisperのStart内では、テンソル演算に使用するオペレーションやニューラルネットワークを実行するインスタンスを生成しています。この際にAIモデルを指定すれば、内部でその演算を行ってくれます。
また、 outputTokens には SpeechToText の初期状態を設定するトークンを指定しています。このoutputTokensは音声をデコードする際に利用します。さらに LoadAudioでは単にAudioClipを浮動小数点配列として取り出し、 EncodeAudio で encoderEngineとspectroEngineによるエンコードを行っています。
void EncodeAudio()
{
// 浮動小数点テンソルを 指定した TensorShapreに併せて生成.
// ここでは data に音声データが含まれているため,音声データをテンソル化している.
// SentisのTensorは IDisposable を持つため usingステートメントを利用する.
using var input = new TensorFloat(new TensorShape(1, numSamples), data);
// Whisperのエンコード/デコードに対しては30秒の音声データを入力しなければならないため,30秒に満たない場合には足りない分を0で埋める.
// Pad out to 30 seconds at 16khz if necessary
using var input30seconds = ops.Pad(input, new int[] { 0, 0, 0, maxSamples - numSamples });
// 音声データをlog-melスペクトル変換して特徴量を計算する.
spectroEngine.Execute(input30seconds);
// 変換結果をTensorで出力する.
var spectroOutput = spectroEngine.PeekOutput() as TensorFloat;
// 音声データの特徴量を Whisperエンコーダーに入力する.
encoderEngine.Execute(spectroOutput);
// エンコード結果を受け取る.
encodedAudio = encoderEngine.PeekOutput() as TensorFloat;
}EncodeAudio メソッド内ではロードした音声データをWhisperエンコードしています。この処理自体は非常に簡単で、音声データからテンソルを生成して、log-melスペクトル変換、エンコード、と順に行っているだけでした。ただ、Whisperでは音声データの長さが30秒であることを基準としています。短すぎる音声ではその推論の制度が低下すると考えられているからのようです GithubDiscussion。その影響でこのサンプル内では足りない分のデータを0で埋めて処理しています。
void Update()
{
if (transcribe && currentToken < outputTokens.Length - 1)
{
// outputTokensをデコーダーに入力するためにテンソルに変換する.
using var tokensSoFar = new TensorInt(new TensorShape(1, outputTokens.Length), outputTokens);
// デコーダーへの入力情報を作成.
var inputs = new Dictionary<string, Tensor>;
{
{"encoded_audio",encodedAudio },// EncodeAudioで生成したエンコード済み音声データ.
{"tokens" , tokensSoFar }
};
// デコーダーに入力して実行.
decoderEngine.Execute(inputs);
// 実行結果を受け取る.ここでは各トークンに対してどの程度一致しているかの数値が返される.
var tokensOut = decoderEngine.PeekOutput() as TensorFloat;
// 出力されたトークンの中から最も大きな数値を持つ(一致している)トークンを探す.
using var tokensPredictions = ops.ArgMax(tokensOut, 2, false);
tokensPredictions.MakeReadable();
// 一致していると判断されたトークンのIDを取得.
int ID = tokensPredictions[currentToken];
// 出力トークンとして記憶する. 次のフレームでの推論にまた利用する.
outputTokens[++currentToken] = ID;
// 推論が終了したと判断されるか,IDが用意されたトークンを超えるまで繰り返す.
if (ID == END_OF_TEXT)
{
transcribe = false;
}
else if (ID <= tokens.Length)
{
outputString += $"(time={(ID - START_TIME) * 0.02f})";
}
// tokensにはvocab.jsonからトークンと単語の組み合わせが含まれているので,その中の指定のトークンを取り出す.
// ここで tokens[ID] は新たに推論された単語となる.
else outputString += GetUnicodeText(tokens[ID]);
Debug.Log(outputString);
}
}Updateは毎フレーム実行されるため、デコーダーによるテキストの推論を少しずつ進めて行くように処理されます。outputTokens はデコーダーへの入力とするためにテンソルに変換され、またデコーダーから推論されたトークンを新たに指定し、次のフレームでまた入力として利用されるようにループしています。デコーダーは事前にモデルを読み込まれたdecoderEngineで実行されます。通常入力された音声データと前回の結果トークンから次のトークンを推論しています。デコーダーからの出力は、vocab.jsonに含まれるすべてのトークンに対してどの程度一致しているかを数値で出力します。そのため、最も大きな数値を持つインデックスを見つければそれが推論されたトークンとなります。推論されたトークンから単語を取得し毎フレームつなぎ合わせることで結果の文章が得られます。
以上、大ざっぱですがサンプルについてその仕組みを記述しました。
今回、このSentisを利用したSpeechToTextを用いて、声で操作するミニゲームを作ってみようと思います。と考えると、音声が30秒限定というのは長くないですか?
AIモデルを出力してみる
Whisperでは短すぎる音声は推論の制度が低下するため30秒の音声ファイルを要求している、ということは理解したうえで、半分の15秒の音声ファイルを処理するモデルを作成してみようと思います。というのも「声で操作するゲーム」を考えたときに、30秒の発言で操作することはほぼないでしょう。15秒でも長いかもしれませんが、ある程度短くできればテンソルサイズが小さくなるのでメモリ節約と処理速度向上が見込めるはずです。
モデル出力スクリプトを利用する
先ほど見たサンプルに含まれる各「.sentisファイル」はonnxAIモデルファイルからUnitySentisが利用しやすいように変換されています。そのため、サンプルにonnxファイルは含まれていません。そこで、そのonnxファイルを手元で出力してみましょう。Whisperのonnxファイル出力もすでに有志によってオープンソース化していますので、こちら whisper-export をお借りします。
今回はWindows+WSL2上のPython3.10.12で実行しました。まず、任意のディレクトリに whisper-export をGitクローンします。その後、以下のコマンドで必要なライブラリをインポートできます。
$ pip install ./
$ pip install onnxCUDAを利用してonnxを出力するため、以下のコマンドでWSL2上でCUDAが参照できているか確認します。CUDAが参照できない場合、NVIDIA Diriverが古いかインストールされていない可能性があります(1ミス)。
$ nvidia-smi
Sun Mar 24 20:50:15 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.10 Driver Version: 551.61 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+私のWindows環境では NVIDIA Driverが551、CUDAが12.4でした。 whisper-export では torch2.2.1がインストールされるので、CUDAのバージョンを12.1以上に合わせる必要があります(1ミス)。また、CUDAのバージョンが合っていてもPythonから認識されない場合があるので、以下のコマンドで状況を確認します。認識されていない場合にはPCの再起動が必要です(1ミス)。
$ python
Python 3.10.12 (main, Mar 15 2024, 20:29:42) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
Trueここまでのコマンドで設定が確認できたら、いよいよonnxモデルを出力しましょう。以下の2つのコマンドを実行し、エンコーダーとデコーダーをそれぞれ出力します。また、この際になんでも良いので音声ファイルが1つ必要です。元になるモデルはwhisper-tinyです。
$ python cli.py audio.wav --model tiny --device cuda --export_encoder
$ python cli.py audio.wav --model tiny --device cuda --export_decoderコマンドが正常に完了すると、export_model ディレクトリにdecoder.onnxとencoder.onnxファイルが出力されています。
また、今回の目的は音声データの認識サイズを30秒から15秒に変更することです。これはこのプロジェクト内のaudio.pyでCHUNK_LENGTHを15に変更するだけでした。
出力したモデルをSentisで使用する
手元で出力したモデルを利用するため、先ほど出力した2つのonnxファイルをサンプルプロジェクトのStreamingAssetsではないディレクトリにコピーします(1ミス)。すると、Inspectorには以下の画像のようにonnxファイルを認識した状態の情報が表示されます。ここで入出力の形も確認できるようです。
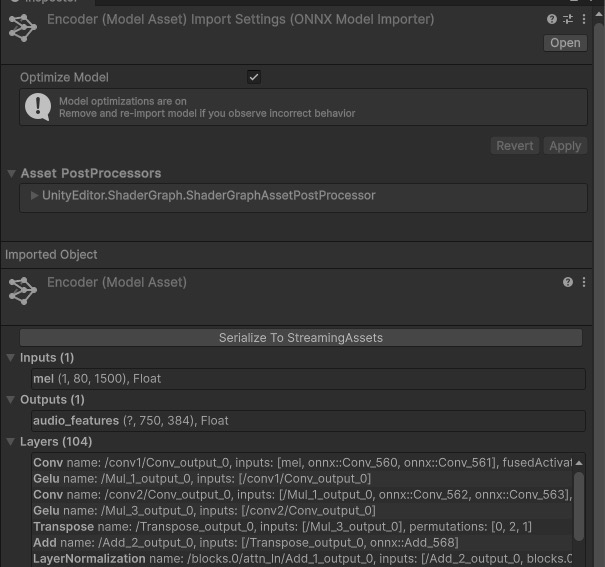
ここで、Inspectorにある[Serialize To StreamingAssets]ボタンを押すと、StreamingAssetsディレクトリにonnxをSentis用に変換した.sentisファイルが出力されます。サンプルに含まれていた.sentisファイルはこのようにして作られたものです。
これでエンコーダーとデコーダーの2つの.sentisファイルが生成されたので、サンプルに含まれていたRunWhisper.csをこのモデルを利用できるように書き換えましょう。LogMelSepctro.sentisはそのまま利用させてもらいます。
まず、以下のように単に読み込むAIモデルのファイル名を変更します。
Model decoder = ModelLoader.Load(Application.streamingAssetsPath + "/decoder.sentis");
Model encoder = ModelLoader.Load(Application.streamingAssetsPath + "/encoder.sentis");さらに、サンプルに含まれていたデコーダーと、手元で生成したデコーダーでは入力データの数が異なります。はじめにmaxSamplesで音声の長さを指定しているので15秒とします。さらにkvCacheとoffsetの2つのテンソルを用意し入力に加える必要があります。
const int maxSamples = 15 * 16000;
TensorFloat kvCache;
TensorInt offset;
void Start()
{
~~~~~~~~~~~~~~~~~~~~~~~
int kvCacheFixed = 451; // whisper-exportで固定された数値.
int beamSize = 1; // 推論探索深さ.
int modelSize = 384; // whisperモデルごとの数値,ここではtiny用.
kvCache = TensorFloat.Zeros(new TensorShape(8, beamSize, kvCacheFixed, modelSize));
offset = new TensorInt(new TensorShape(1), new int[] { 0 });
}
void Update()
{
if (transcribe && currentToken < outputTokens.Length - 1)
{
using var tokensSoFar = new TensorInt(new TensorShape(1, outputTokens.Length), outputTokens);
var inputs = new Dictionary<string, Tensor>
{
{"audio_features",encodedAudio },
{"tokens" , tokensSoFar },
{"offset", offset},
{"kv_cache", kvCache }
};
decoderEngine.Execute(inputs);これで手元で出力したwhisperのAIモデルを使用する準備が整ったので、Unityをプレイします。
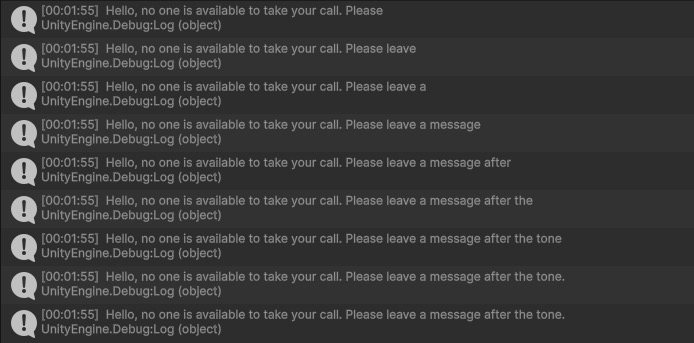
ログに出力される結果はサンプルとまったく同じです。
ここで、音声の長さを15秒としたことが正しく反映できているかは以下のログを出力すると確認できます。
Debug.Log($"encodedAudio: {encodedAudio.shape}");このとき出力されるのは音声がエンコードされた後のテンソルの形状です。30秒のとき、15秒のときでそれぞれログは以下のようになります。
# 30秒のとき
encodedAudio: (1, 1500, 384)
# 15秒のとき
encodedAudio: (1, 750, 384)これで手元で出力したAIモデルが利用できていることを確認できました。
音声で操作するミニゲーム
それではSpeechToTextを利用したミニゲームを作ってみましょう。
まずは音声を認識せずに、キーボードで動かす簡素なゲームを作ります。
出来上がったものがこちら

キーボードでユニットを操作し箱を指定の位置まで移動させます。画面中央にはその時ユニットに与えられた命令を表示しています。現状はキーボードからこの命令を与えていますが、ここに音声認識を組み込んでいきましょう。
音声をリアルタイムに処理する機構
これまでのサンプルでSpeechToTextする際の音声データはwavファイルになっていました。「音声で操作」するためにはマイクからの入力をリアルタイムに変換していく必要があります。この機構を作りましょう。
まず、Unityでデバイスのマイクを利用するには以下のように記述します。モバイル端末ではマイクの利用許可ダイアログの表示が必要ですが、現在Macで動作させているのでこれだけの処理でマイクを利用できます。
if (Microphone.devices.Length == 0)
{
Debug.Log("microphone not found");
return;
}
microphoneName = Microphone.devices[0];
Debug.Log("find microphone : " + microphoneName);
audioClip = Microphone.Start(deviceName: microphoneName, loop: true, lengthSec: audioSecondLength, frequency: audioFrequency);このコードによってaudioClipからはマイクから入力された音声がそのままAudioClipとして参照できるので、以下のようなコードでそのデータを取得できます。
// AudioClipの現在の位置.
int position = Microphone.GetPosition(microphoneName);
if (position < 0 || position == prevSamplePosition) return;
// 全データをバッファに取得.
audioClip.GetData(dataBuffer, 0);
// 前回確認した位置と現在の位置を比較.
if (position < prevSamplePosition)
{
// 前回の位置のほうが大きい場合はループを挟んでいるのでループを考慮してdataに格納.
data = new float[position + (audioFrequency * audioSecondLength - prevSamplePosition)];
Array.Copy(dataBuffer, prevSamplePosition, data, 0, audioFrequency * audioSecondLength - prevSamplePosition);
Array.Copy(dataBuffer, 0, data, audioFrequency * audioSecondLength - prevSamplePosition, position);
}
else
{
// 現在の位置のほうが大きいので進んだ分をdataに格納.
data = new float[position - prevSamplePosition];
Array.Copy(dataBuffer, prevSamplePosition, data, 0, position - prevSamplePosition);
}
prevSamplePosition = position;
// 音声がしきい値を超えているか確認.
bool isVoice = false;
for (int i = 0; i < data.Length; i++)
{
if (Mathf.Abs(data[i]) > audioThreshold)
{
isVoice = true;
break;
}
}
// データ点の内1つでもしきい値を超えていれば音声データとして扱う.
if (isVoice)
{
var bf = processData;
processData = new float[bf.Length + data.Length];
Array.Copy(bf, 0, processData, 0, bf.Length);
Array.Copy(data, 0, processData, bf.Length, data.Length);
}
else
{
// しきい値を超えなかったので無音と判断.
processData = new float[0];
}このときのAudioClipはループがONになっているので、指定の秒数を過ぎると0に戻って音声が上書きされるような動作をします。そのため、前回確認した音声の位置と現在の位置が逆転している場合にはループを挟んでいるのでそれを考慮してデータを取得しなければいけません。また、すべての音声を常にSpeechToText処理をするのも無駄なので、取得したデータがしきい値を超えているかどうかで無音の判定をする必要があります。
こうして取得した音声データをWhisperエンコーダー・デコーダーで処理することで、リアルタイムにSpeechToTextを行うことができます。その様子を録画しました。左上の白い囲いの中に、現在マイクから入力されている音声をリアルタイムにテキスト変換して表示しています。言葉が止まると途中で[BLANK_AUDIO]が認識されてしまいますが、概ね正常に変換されているようです。We'll sail ~~の部分は始めにI'll say will youなどと認識されていますが、これは認識中の音声データが短すぎるために正確な推測ができていないためで、続きの音声が順に認識され始めると一気に正確な推測ができています。
Today is the best day of my life. So I'm going to explore the world with my rabbits. We'll sail, we'll ride through the wilderness, we'll climb mountains, and we'll leave this earth one day.

以上、無事に喋った言葉がテキストに変換されました。これだけでもオンラインマルチプレイなどで文字起こし機能として利用できそうですね。
変換されたテキストをコマンドとしてユニットを動かす
音声から変換されたテキストにユニットの操作コマンドが含まれていたとき、その動作を実行するようにしました。同時に変換されたテキストは右下に表示しています。これによって、音声でユニットを操作することができるようになりました。

まず反省点として、とんでもなく難しいです。音声がテキストに変換されるまで1秒ほどかかってしまうので、その間にユニットは動き続けてしまい、操作しようにも間に合っていませんでした。また、ユニットを操作するコマンドが一つの単語なので、短い音声を正確に推論できないという点がネックになり、結果として短文で話しかけなければなりませんでした。声で操作するという趣旨としてはミニゲームの選定に失敗しました。
しかしながら入力した音声をリアルタイムにテキスト変換できるということは、ゲームで幅広く活用できるのではないでしょうか。大きな可能性を秘めているように感じます。
まとめ
今回はUnitySentisに触れるという目的で、まずWhisperのサンプルを動作させてそのコードをある程度理解しました。さらにwhisper-exportを利用してSentisで使用するWhisperのonnxを出力できるようになりました。このとき音声の長さを半分の15秒に変更できました。ここから音声をコマンドとしたミニゲームを作成し、マイクからの入力を常にSpeechToText変換することでゲーム内のユニットを操作できるようになりました。
このプロジェクトだけでもUnitySentisを利用することでAIモデルを気軽に扱えることが理解できるのではないでしょうか。ゲームからAIを利用する際にネットワークインフラに依存しないという点は強力だと思います。夢が広がりますね。























 Peatix
Peatix Wantedly
Wantedly