
 とAIエージェントによるゲームデータ分析の可能性")
目次
2025GWはパウンドケーキを焼きました。ファンカルチャー・デザイン学部 中村です。
前回の記事ではLLMを利用したAIエージェントによるデータ分析を試すためにダミーデータを用意して、いくつかのプロンプトを指示してデータ分析を行いました。記事中でも触れましたが、AIエージェントにアップロードするcsvファイルにはサイズ制限が存在します。実際に運営しているタイトルのデータを分析しようとしたときにはそのサイズ制限がネックになってしまうでしょう。そのため、AIエージェントから直接データベースに対してクエリを実行してもらう必要があります。
しかしながら、ChatGPTやClaude、Geminiに代表されるようなAIエージェントがデータベースに接続するとはどういうことでしょうか。Model Context Protocol (MCP)という仕組みを利用して、実際に postgres へ接続する方法を見ていきましょう。
Model Context Protocol (MCP)
2024年11月に Anthropic から MCP が発表されました。以下に、Anthropicの発表から引用します(Google翻訳)
本日、私たちはモデルコンテキストプロトコル(MCP)をオープンソース化します。これは、コンテンツリポジトリ、ビジネスツール、開発環境など、データが存在するシステムにAIアシスタントを接続するための新しい標準です。その目的は、最先端のモデルがより優れた、より適切な応答を生成できるようにすることです。
https://www.anthropic.com/news/model-context-protocol
問いかけることで様々な応答を返してくれるAIエージェントは、その発展によって精度が向上し幅広い分野での利用が想定されます。このとき、AIエージェントとデータが切り離されていることが利用拡大の障壁となります。そこで、AIエージェントとデータソースを接続するための仕組みがMCPなのです。
仕組み
MCPの仕様やGet Startedはこちらに記載されています。構成の画像もお借りしています。
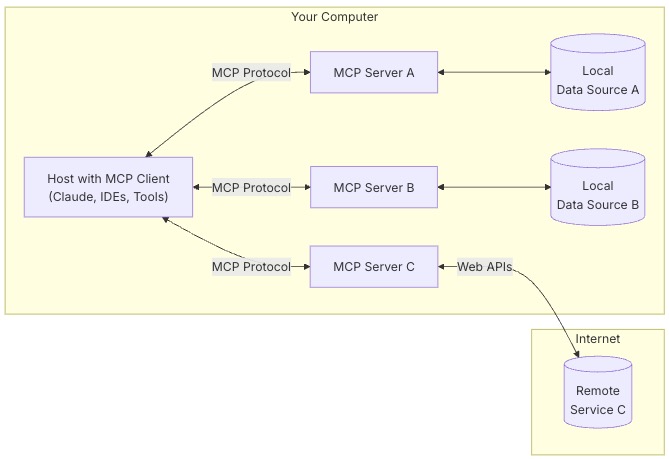
AIエージェント(Host With MCP Client)から何らかのデータ(Local Data Source)へ接続する場合、その間にMCP Serverを起動します。これによってAIエージェントはこのMCP Serverを経由してデータを取得可能となります。同じく何らかのWebサービスへ接続させたい場合も、専用のMCP Serverを起動する必要があります。このように、AIエージェントとMCP Server間の通信で用いられているデータ構造がMCP Protocolです。
MCP Serverは接続するデータソースやWebサービスに応じた機能が求められます。すでに Google Drive や Slack、Githubなど多くのWebサービスに対応したMCP Serverが開発されており、一覧として提供されています。つまり、例えばAIエージェントに対してGithubのコミットログを参照させ、特定の情報を抽出したり、レポートを作成したりといったことが可能になります。独自のニーズに合わせてカスタムしたMCP Serverを開発することも可能です。
MCP Clientを手軽に試すのであれば、Claude Desktopが最適です。開発者設定から構成をONにし、設定ファイルに適宜利用したいMCPサーバーを指定するだけで済みます。
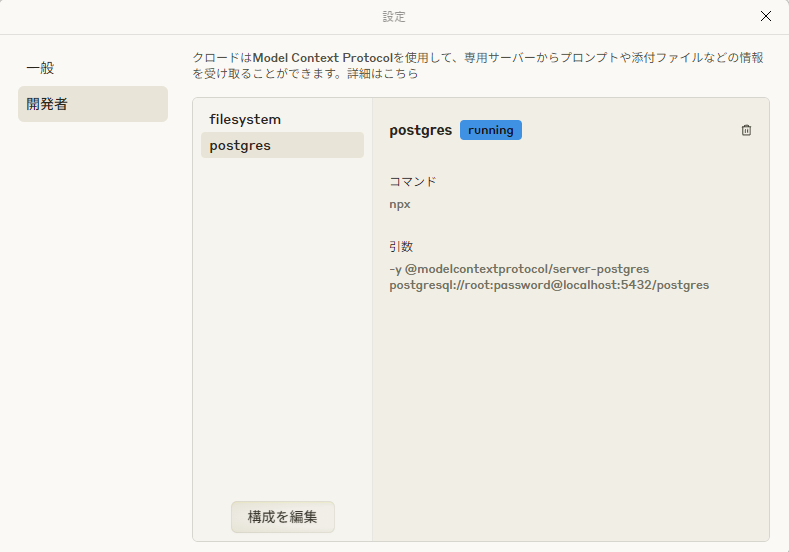
しかしながら、私のFree Plan環境ではおおよそ5回程度の試行でメッセージ上限に到達してしまうため、なかなか実験が捗りませんでした。
いよいよ有料プランへ課金すべきかと考えましたが、せっかくなので Build With Claude からAPI Keyを取得し、Streamlitでやりとりしてみようと思います。
Streamlit
Streamlit はデータ分析を手軽にWebアプリとすることを目的に開発されました。Pythonコードを記述するだけでフロントエンドを考える必要がなく、簡単にデータの可視化や分析ができるフレームワークです。そのため生成AIを利用する場面でも非常に簡単にチャットツールが作れてしまいます。
まず、単にClaudeとやり取りするだけのチャットWebアプリを実装してみます。Python環境は uv で用意しました。
$ uv init
$ uv add anthropic streamlit import anthropic
import streamlit as st
API_KEY = 'sk-xxxxxxxxxx'
AI_MODEL = 'claude-3-7-sonnet-20250219'
st.title("MCP App")
client = anthropic.Client(api_key=API_KEY)
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
st.chat_message(message["role"]).markdown(message["content"])
if prompt := st.chat_input("May I help you?"):
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").markdown(prompt)
with st.spinner("Thinking..."):
response = client.messages.create(
messages=st.session_state.messages,
model=AI_MODEL,
temperature=0.7,
max_tokens=1024,
)
st.session_state.messages.append({"role": "assistant", "content": response.content[0].text})
st.chat_message("assistant").markdown(response.content[0].text)
st.rerun()uv で anthropic と streamlit をプロジェクトに追加し、上記コードを記述します。その後、以下のstreamlitコマンドを実行します。
$ streamlit run streamlit-app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501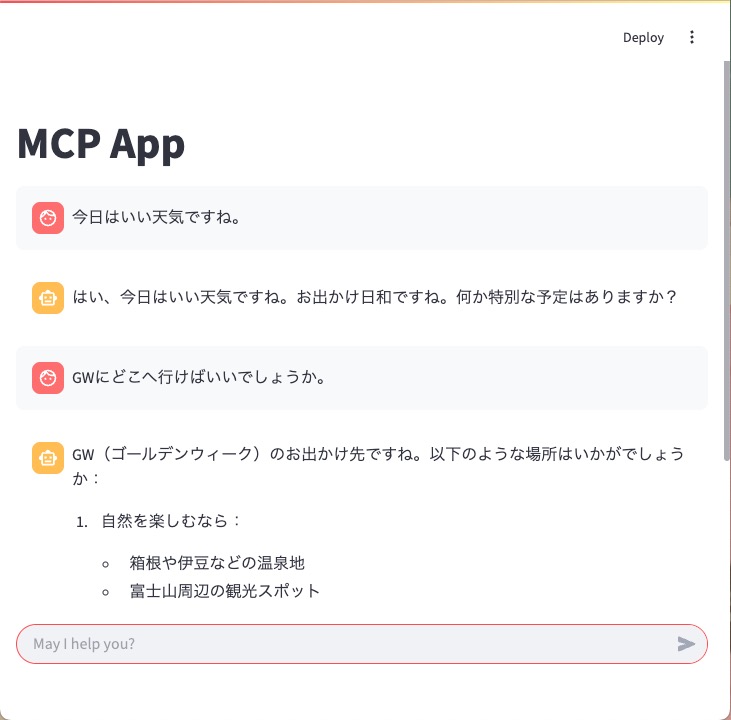
以上のようにClaudeと会話するチャットボットWebアプリが完成しました。その他、履歴の表示やモデルの選択なども追加することもできますが、単純に会話するだけならこれだけでも十分です。
それではこれをもとにしてMCP ServerとやりとりするAIエージェントを作成しましょう。
MCPエージェント
とは言え、すでに先人たちがStreamlitで利用できる mcp-agent を開発しているので利用させていただきます。まず uv からプロジェクトへ追加します。
$ uv add "mcp-agent"以下のようにMCPエージェントが参照するMCPサーバーをconfigファイルに記載します。
$schema: schema/mcp-agent.config.schema.json
execution_engine: asyncio
logger:
type: console
level: debug
batch_size: 100
flush_interval: 2
mcp:
servers:
postgres:
command: npx
args:
- -y
- "@modelcontextprotocol/server-postgres"
- postgresql://root:password@localhost:5432/game
# openai:
# # Secrets (API keys, etc.) are stored in an mcp_agent.secrets.yaml file which can be gitignored
# default_model: gpt-4o
anthropic:
default_model: claude-3-7-sonnet-20250219今回はpostgresデータベースのデータを参照するので@modelcontextprotocol/server-postgres を利用します。server-postgres は npx で動作するため事前にインストールしておくと良いでしょう。オプションでは単にローカルのDockerで起動したpostgresのエンドポイントを指定しています。
streamlit から mcp-agent を利用するために、以下のようなエージェントを記述します。
async def streamlit_input_callback(request: HumanInputRequest) -> HumanInputResponse:
return HumanInputResponse(request_id=request.request_id, response="Approved.")
async def get_agent():
"""
Get existing agent from session state or create a new one
"""
if "agent" not in st.session_state:
mcp_agent = Agent(
name="MCP Agent",
instruction="*** System Propmt ***",
server_names=["postgres"],
connection_persistence=False,
human_input_callback=streamlit_input_callback,
)
await mcp_agent.initialize()
st.session_state["agent"] = mcp_agent
if "llm" not in st.session_state:
st.session_state["llm"] = await st.session_state["agent"].attach_llm(AnthropicAugmentedLLM)
return st.session_state["agent"], st.session_state["llm"]MCP ClientはエージェントからMCP Serverへの接続を許可するために認証が必要です。streamlit_input_callback でその承認を行っています。エージェントに関しては mcp-agent で用意されたクラスをシステムプロンプトとともに初期化することで生成できます。また、生成されたエージェントには AnthropicAugmentedLLM でClaudeを利用するよう設定しています。 さらに以下のように mcp-agentのAppを初期化します。
app = MCPApp(name="MCPChat", human_input_callback=streamlit_input_callback)
async def main():
await app.initialize()
# streamlit code below
if __name__ == "__main__":
asyncio.run(main())MCPAppは初期化を async/await を用いるため、streamlitのコードを記述する前に済ませておく必要があります。そのために asyncio.run で初期化処理を実行しつつstreamlitコードを記述すべきです。MCP Agentとチャットベースでやり取りする streamlit コードは以下のとおりです。
agent, llm = await get_agent()
if prompt := st.chat_input("Type your message here..."):
st.session_state["messages"].append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
with st.spinner("Thinking...", show_time=True):
request_params = llm.default_request_params
request_params.maxTokens = 8192
response = await llm.generate(
message=prompt,
request_params=request_params,
)
for msg in response:
st.session_state["messages"].append({"role": "assistant", "message": msg})
st.rerun()ここでは mcp-agentで生成された llm に対してユーザーのプロンプトを送信しています。MCP Serverとの通信中、エージェントは内部で複数の処理を実行しており、その結果として複数のメッセージがまとめてレスポンスとして返されます。
以上でmcp-agentを利用してMCP Serverとのやり取りができるようになります。
postgresデータベースと接続する
仮データ
MCPエージェントがpostgresデータベースへ接続できているのか確認するための仮データを用意します。構造は前回の記事と同じく以下のようにしています。
| code | name | start_at | end_at | detail |
|---|---|---|---|---|
| event_001 | 大冒険!! スキー大会イベント | 2024-01-10 | 2024-01-24 | 草属性キャラクターの素早さアップ, 闇属性キャラクターの防御力アップ |
| id | name | registered_at | rank | device | country_code |
|---|---|---|---|---|---|
| 1 | 杏奈 | 2024-01-01 03:57:25 | 41 | iOS | JP |
| player_id | event_code | progress | created_at |
|---|---|---|---|
| 1 | event_007 | 164 | 2024-06-02 03:57:25 |
| player_id | created_at |
|---|---|
| 1 | 2024-01-01 03:57:25 |
また、前回の記事で挙げたLLMのアップロードサイズ制限に対して、postgresデータベースを用いることでこの課題を克服できることを示すため、player_data を20万件、player_login_logs を7200万件用意しました。
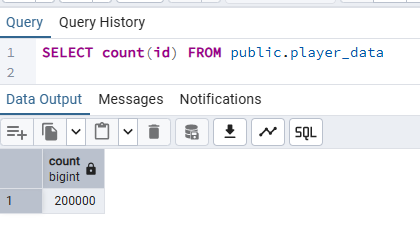
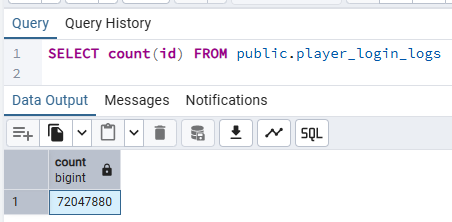
それではMCPエージェントからこれらの仮データへ接続してみましょう。
MCPエージェントへのプロンプト
まず、エージェント自身のシステムプロンプトを定義します。以下のとおりです。
* あなたはPostgreSQLのデータベースにアクセスできるエージェントです.
* ユーザーからの指示に従ってデータベースにアクセスしてください.
* ユーザーはそのデータベースのデータを分析したいと思っています.
* 視覚化する場合には必ずHTML、Javascript、chart.jsを使用し、このときHTMLコードをmarkdownで出力してください.
* chart.jsのcanvasは高さ制限を200pxとしている点に注意してください.
* 複数のチャートを表現する場合には必ず別のhtmlとして分割して下さい.
* PostgreSQLによるクエリ結果は必ずHTMLとは別でjsonでも出力してください.
* また、ツールを使用するかどうかはエージェントが判断できます.基本的な方針として、エージェントにはデータベースへ接続したうえでユーザーの希望を叶える動きを行います。ただし、視覚化についてはstreamlit標準のチャートを利用するための調整が困難なため、HTMLを生成する方式を採用しています。生成されたHTMLをstreamlitの components.v1.htmlでiframeに描画します。
それでは、データベースへの接続を確認するために以下のプロンプトを実行します。
postgresにはどのようなテーブルがありますか?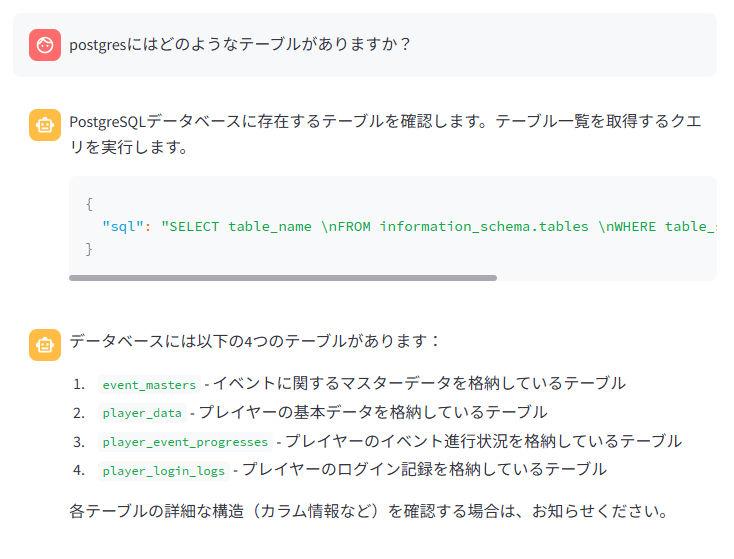
postgresデータベースへの接続に成功しました。また、それぞれのテーブルの特徴についても理解できました。
さらに以下のプロンプトで視覚化も確認しましょう
player_data テーブルからユーザー数をrankでビニングしてプロットしてください
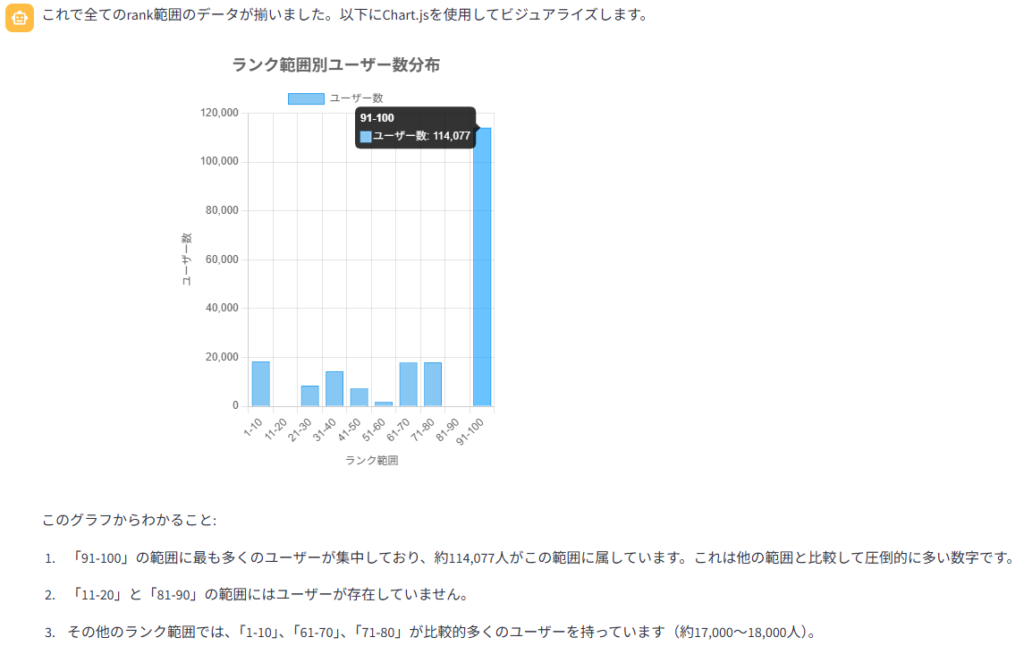
player_data テーブルの構造を理解し、指定された rank でのビニングを実行しました。グラフから読み取れる内容についても説明しています。これにより、データベースへの正常な接続とチャートの表示機能が確認できました。
それでは本題です。ゲームデータを分析しましょう。
ゲームデータを分析
ここまでの準備でMCPエージェントからpostgresデータベースへ接続できることが確認できました。これを利用してゲームデータの分析が可能です。
しかしながら
前回の記事ではGeminiとの一問一答のような形で、各種データの可視化と分析を行っていきました。AIエージェントを活用する上で、データ分析の進め方には様々なアプローチが考えられます。個人的には、AIエージェントが自律的に分析を進めてくれることが理想です。
というわけで、一旦履歴をリフレッシュした状態で以下のプロンプトを実行しました。
postgresデータベースにはスマートフォンゲーム「AAA Heroes」に関するイベントとプレイヤーのデータが保存されています。 このデータを"イベントの盛り上がり"について分析したいと考えていますが、どのような分析をすればよいでしょうか。テーブル構造を確認し、分析手法を複数提案してください。「AAA Heroes」というのはわたしがダミーデータを生成するときに使う仮名です。非常に曖昧な表現として”イベントの盛り上がり”を分析せよと指示します。5分程度の長考の後、テーブルデータ構造を確認するクエリの後に以下の回答がありました。
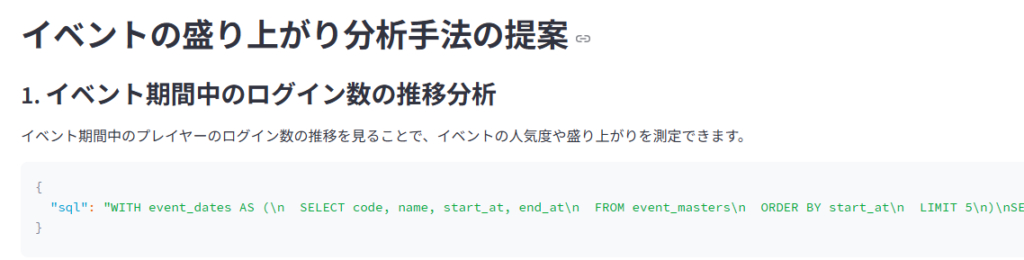
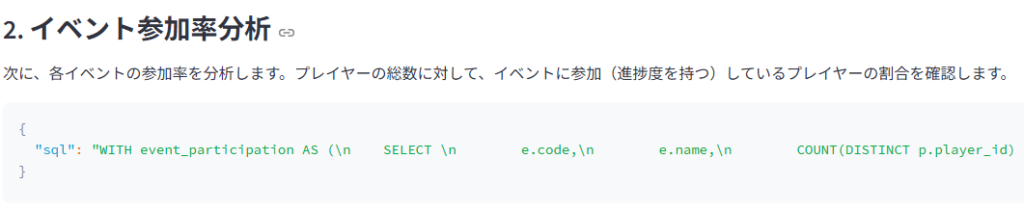

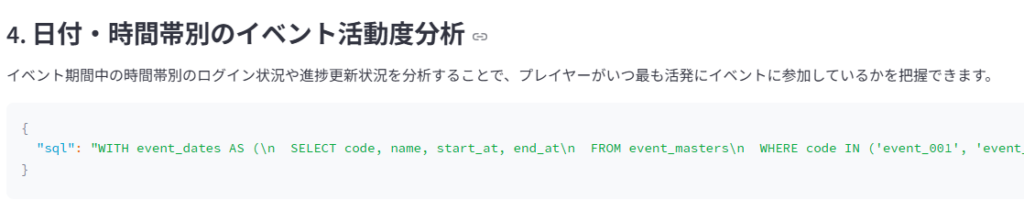
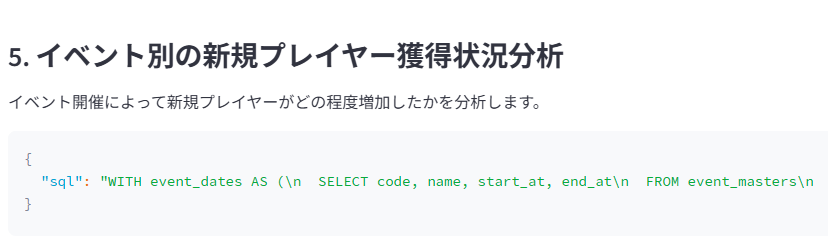
AIエージェントから5種類の分析手法が提案されました。それぞれの提案には対応するクエリが示されており、個別に確認できます。これらの提案は、プレイヤーのログイン数、イベント進捗度合い、参加率に基づいてイベントの盛り上がりを分析しようとしており、妥当な方針と言えるでしょう。
続けて以下のプロンプトを実行し、回答を得ました。
> 1. イベント期間中のログイン数の推移分析
についてグラフをプロットし、それについてあなたの意見を聞かせてください
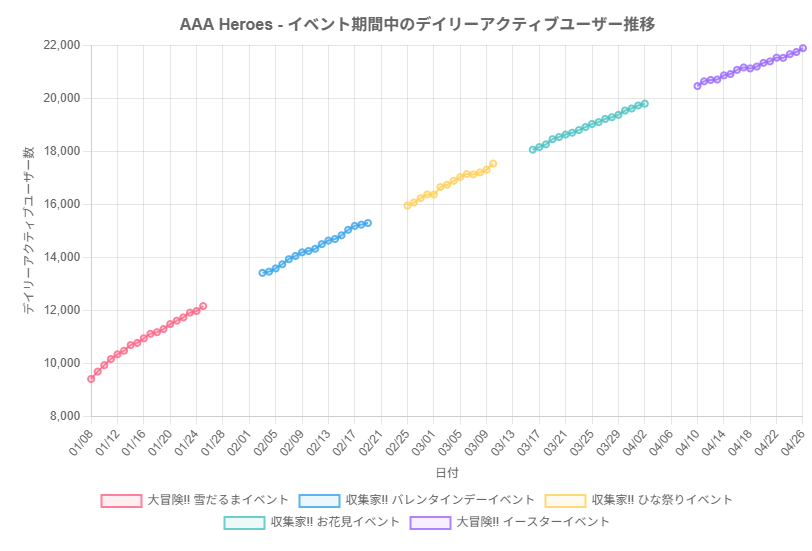


提案された分析手法の1つに関してグラフをプロットさせ、それに対するAIエージェントの意見を確認することができました。「効果的なイベントサイクルがユーザーベースを維持・拡大している」「イベントがユーザーエンゲージメントの持続性に貢献している」など、かなり褒めてくれますね。改善提案も出してくるとはなかなか気が利いてますね。
続けて、次の分析手法についても質問しましょう。
> 2. イベント参加率分析
についてグラフをプロットし、あなたの意見を簡潔に教えてください。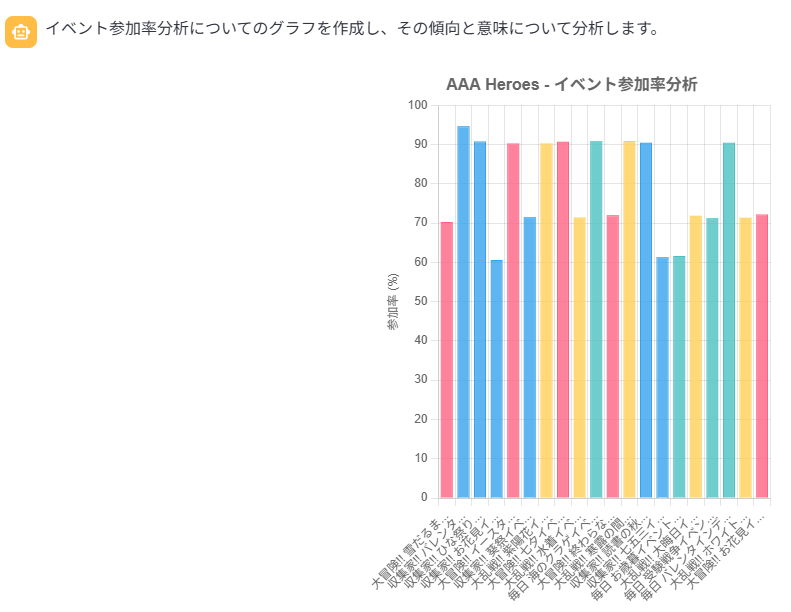

「簡潔に」と指示したので、意見がかなり見やすくなりました。イベントのタイトルに含まれる文字列でその差異を分析しているようです。できれば event_masters.detail カラムの情報を見てほしかったところですが、そういった要望は最初のプロンプトで指示しておくべきでした。
こういった形で、AIエージェントから出てきた手法に対して、気になる点、確認すべき点を追加の質問で深く理解していくというのは非常に有用な使い方だと思います。残り3つの分析手法がありますが長くなってしまうので、以下のプロンプトで一旦まとめさせてみましょう。
ここまでの分析をもとに、スマートフォンゲーム「AAA Heroes」のイベントの盛り上がりについて簡潔にまとめてください。


2つの手法についてプロットと分析をしたので、その内容をまとめさせました。「特に成功しているイベント」「改善の余地があるイベント」として、現状と発展についてAIエージェントの意見を述べています。
さて、前回の記事でも最後に実行した以下のプロンプトで、次回イベントの提案を確認してみましょう。
次回イベントは 2025-05-17 からの開催を予定しています。どのようなイベントを行うと良いでしょうか?
非常に長い文章が出力されました。「命名」「内容」「効果」「参加促進」ではどのようなイベントを実施すべきかを簡潔にまとめています。まさか「予測される結果」まで提示してくるとは思いませんでした。この通りに実施してDAUが5%増加するのであれば素晴らしい限りです。しかしながら、「2.イベント内容の提案」で「水属性と月属性の新キャラクターを期間限定で実装」とありますが、新規属性の実装などそう簡単にできるものではないと思います。そういったところの取捨選択は必要になるでしょう。AIエージェントに対しては、ある程度方針があるなら(工数を短く等)事前に提示しなければなりません。
ただ、AIエージェントがデータを見てこういった提案をしてくるというのは非常に便利で参考になります。
最後に
今回はAIエージェントからpostgresデータベースへ接続するため、Model Context Protocol (MCP)に基づいてstreamlitとmcp-agentで環境を構築しました。先人たちが構築したフレームワークとプラグインによって、かなり手軽に実装することができました。
AIエージェントがデータベースのデータを参照できるようになったことで、データ分析の幅が大きく広がったと思います。常に参照できる状態にしておけば、いつでもその洞察を得ることができます。ただ、本来データ分析基盤としてはpostgresデータベースにクエリを実行するべきではなく、AWS S3+AthenaやBigQuery、Snowflakeなどを利用すべきでしょう。すでにそれぞれに合ったMCP Serverも公開されているので、今回紹介した方法でも問題なく実行できます。
MCPはまだまだ使い道が広がりそうです。
中村翔吾
ファンカルチャー・デザイン学部
個人でゲーム開発をしている。うさぎ2羽の世話係。






















 Peatix
Peatix Wantedly
Wantedly