

目次
自宅のLANケーブルを6Aに敷設し直したいと思っています。ファンカルチャー・デザイン学部 中村です。
最近のLLMはcsvをアップロードすることでそのデータを分析することができます。特にClaudeのanalysis toolが強力なようですが、ChatGPTでもGeminiでも同様の分析ができてしまいます。実際にどのような分析ができるのか試していきましょう。
ゲームデータの分析
わたしはゲーム部門に所属しているので、ソーシャルゲームを運営しているとユーザーの行動に関する様々なデータが集まることがよくわかります。しかしながら、多数のデータをどのように分析すればいいのか、予測と合っているか、効果測定は正しいのか、活かせているか、等はなかなか難しいところがあります。それらについてLLMから何らかの提案や洞察が得られるとしたら、それは素晴らしいことでしょう。
仮データを用意する
ソーシャルゲームのそれらしい仮データを用意します。今回は特にソーシャルゲームによく見られる「イベント」に関してデータを用意し分析したいと思います。分析されることを考慮してある程度偏りが出るようなデータをPythonで生成します。
まず、イベントの基本情報として event_master.csv と player_data.csv をよくありそうな形で定義します。event_master には2024年1月から2025年5月までのイベント情報を21件、player_dataにはユーザー情報を100件用意しました。
| code | name | start_at | end_at | detail |
|---|---|---|---|---|
| event_001 | 大冒険!! スキー大会イベント | 2024-01-10 | 2024-01-24 | 草属性キャラクターの素早さアップ, 闇属性キャラクターの防御力アップ |
| event_002 | 毎日 節分イベント | 2024-01-31 | 2024-02-19 | 草属性キャラクターの素早さアップ, 火属性キャラクターの素早さアップ, 雷属性武器の出現率大幅アップ |
| event_003 | 大乱戦!! ホワイトデーイベント | 2024-02-26 | 2024-03-15 | 草属性キャラクターの攻撃力大幅アップ, ショップの全商品半額, 獲得経験値2倍, 消費アイテムドロップ率増加 |
| id | name | registered_at | rank | device | country_code |
|---|---|---|---|---|---|
| 1 | 杏奈 | 2024-01-01 03:57:25 | 41 | iOS | JP |
| 2 | 大輝 | 2024-01-01 03:20:44 | 30 | iOS | JP |
| 3 | Nora | 2024-01-01 12:17:12 | 36 | Android | TW |
さらに、イベントに参加したユーザーの進捗データとして player_event_progress.csv を500件、ユーザーがログインした履歴データとして player_login_logs.csv を4,000件それぞれ用意しました。
| player_id | event_code | progress | created_at |
|---|---|---|---|
| 1 | event_007 | 164 | 2024-06-02 03:57:25 |
| 2 | event_004 | 120 | 2024-04-08 03:20:44 |
| player_id | created_at |
|---|---|
| 1 | 2024-01-01 03:57:25 |
| 1 | 2024-01-04 03:57:25 |
| 1 | 2024-02-02 03:57:25 |
この4つのcsvをGeminiにアップロードしてイベントデータ分析を行います。
データ分析を開始
今回はGemini Advancedの2.0 Flashを利用します。
csvのアップロードとデータ構造の説明と簡単なプロット
csvをGeminiのプロンプト入力画面にドラッグアンドドロップすればアップロードできます。同時にこのデータでどのような分析をしたいのか伝える必要があります。また、何度か試した結果、CSVにどのようなデータが格納されているかの説明も必要だと感じました。そうしないと、以降のプロンプトの意図が伝わらないことが多々ありました。今回はcsvをアップロードしつつ以下のプロンプトを入力しました。

これはスマートフォンゲームに関するイベントとプレイヤーのデータです。
それぞれのcsvには以下の情報が含まれています。
* event_master: 過去に開催したイベント情報
* code: イベントの識別コード
* name: イベント名
* start_at: イベント開始日
* end_at: イベント終了日
* detail: 開催されたイベントの特徴をカンマ区切り
* player_event_progress: プレイヤーのイベントへの参加情報
* player_id: レコードの対象プレイヤーID
* event_code: 参加したイベントの識別コード
* progress: イベントの進捗パラメータ
* created_at: そのイベントに参加した日時
* player_data: 各プレイヤーの情報
* id: プレイヤーの識別子
* name: プレイヤー名
* registered_at: ゲームへの登録日
* rank: プレイヤーの強さを表すランク
* device: プレイヤーの使用端末
* country_code: プレイヤーの国コード
* birthday: プレイヤーの誕生日
* player_login_logs: 各プレイヤーがログインした際の履歴
* player_id: 対象のプレイヤーID
* created_at: ログインした日時
これを分析したいと思います。
まず、プレイヤーの人数を国別でプロットしてくださいすると、Geminiの分析のあと棒グラフが表示されました。表示された棒グラフはマウスオーバーすると詳細情報を確認できるようです。
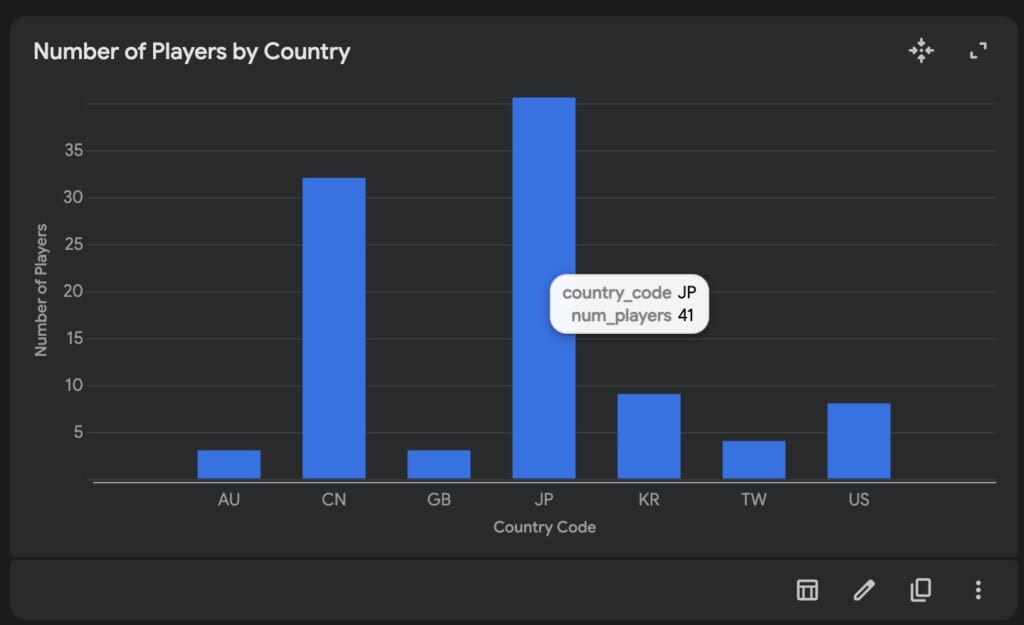
また、「コードを表示」ボタンをクリックするとPythonコードが表示されました。Pythonコードは主にcsvデータの構造確認、pandas を利用した国別での件数カウント、altair を利用したプロットと分割されて実行されているようです。
import pandas as pd
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# Read the CSV files into Pandas Dataframes
df_player_data = pd.read_csv('player_data.csv')
# Display the first 5 rows of each DataFrame
print(df_player_data.head().to_markdown(index=False, numalign="left", stralign="left"))
# Print the column names and their data types for each DataFrame
print(df_player_data.info())# Count the number of players by country
player_counts_by_country = df_player_data['country_code'].value_counts().reset_index()
player_counts_by_country.columns = ['country_code', 'num_players']
# Print the first 5 rows of the dataframe
print(player_counts_by_country.head().to_markdown(index=False, numalign="left", stralign="left"))
# Print the column name and their data types
print(player_counts_by_country.info())
import altair as alt
# Create the bar chart
chart = alt.Chart(player_counts_by_country).mark_bar().encode(
# Set `country_code` to x-axis and set the label as 'Country Code'
x=alt.X('country_code', title='Country Code'),
# Set `num_players` to y-axis and set the label as 'Number of Players'
y=alt.Y('num_players', title='Number of Players'),
tooltip=['country_code', 'num_players'] # Add tooltip
).properties(
title='Number of Players by Country' # Set the title of the chart to 'Number of Players by Country'
).interactive() # Make the chart Interactive
# Save the chart
chart.save('number_of_players_by_country_bar_chart.json')ひとまず入力したcsvを理解してプロットまではできているようです。
MAU(Monthly Active User)をプロット
それでは次に、運営タイトルではよく確認される MAU をプロットさせます。追加で以下のプロンプトを入力しました。
player_login_logs をもとに各月のユーザー数をプロットしてください。これをMonthly Active User(MAU)と定義します。再度Geminiの分析が始まり、その後以下のプロットが表示されました。
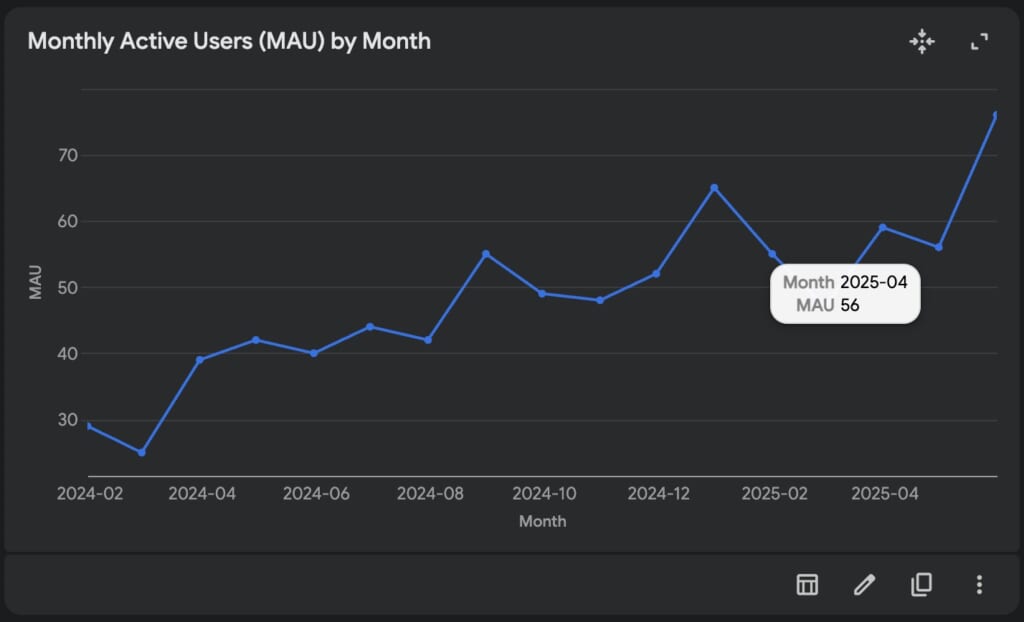
プロットの下部メニューには「表で表示」「グラフをカスタマイズ」「グラフを画像としてコピー」「画像としてダウンロード」「JSONファイルを保存」の機能が搭載されています。「グラフをカスタマイズ」するとグラフの種類やタイトルを変更できます。

イベント参加率を考える
ここまでの操作で視覚化の使い方がおおよそ理解できたので、イベントデータの分析を始めます。
まず、どの程度のユーザーがイベントへ参加したのか確認しましょう。その際に単に参加した人数を確認するだけではなく、アクティブユーザーのうち、何%が参加したかを示す参加率を考えます。各イベントには期間が設定されているため、その期間中にどれくらいのユーザーがアクティブだったのか、そしてそのうち何人が参加したのかをプロットします。
まず、以下のプロンプトでイベント期間中にアクティブだったユーザー数をカウントします。
event_masterにはstart_atとend_atが指定されており、イベント開催期間が設定されています。このイベント開催期間にログインしたユーザーをplayer_login_logsを参照してプロットしてください。X軸はevent_masterのcodeとします。これをEvent Active User (EAU)と定義します。
次に、実際にイベントに参加したユーザー数をカウントします。イベントへ参加するためにはログインする必要があるので、参加ユーザー ≦ アクティブユーザーとなるはずです。以下のプロンプトを実行します。
次に、player_event_progressのデータから各イベントへのユニーク参加者数をプロットしてください。これをEvent Participants User(EPU)と定義します。
それでは参加率をプロットしましょう。参加率は、イベント開催期間中にログインしたユーザー数に対する、実際にイベントに参加したユーザー数の割合で計算できます。そのため、各イベントに対して 参加率 = EPU / EAU となります。以下のプロンプトでプロットします。
各イベントに対して EPU / EAU を計算し、アクティブだったユーザーがどの程度の割合でイベントに参加したかを表すプロットを生成してください。これをイベント参加率とします。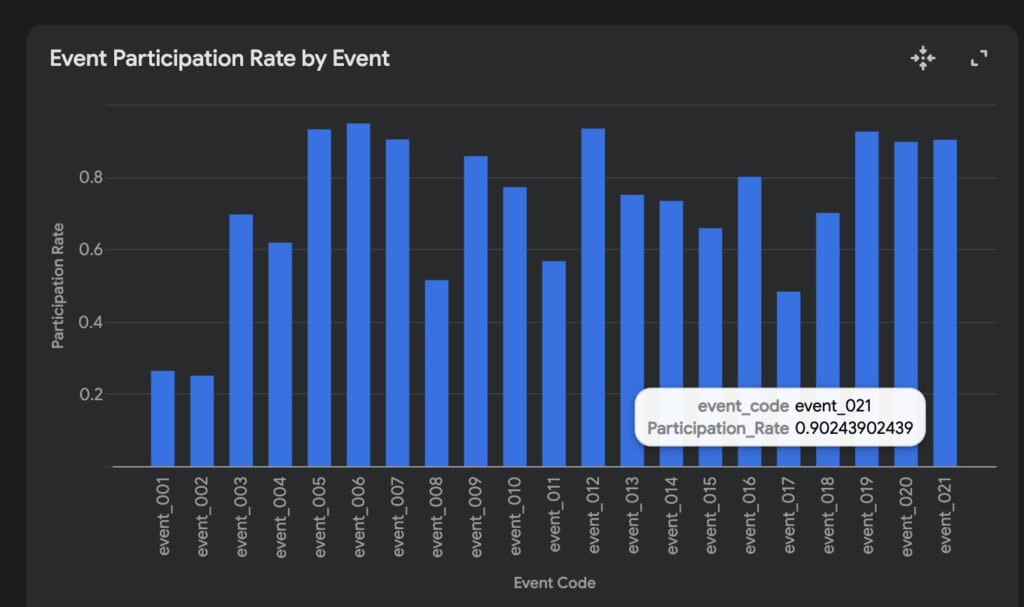
以上のように各イベントの参加率をプロットすることができました。ここまで進めて感じたことですが、EAU・EPUというのはその場で思いつきで作った単語であるにもかかわらず、Gemini側がその定義を理解していることに驚きました。
さて、参加率のグラフを見ると、ところどころ異様に低いイベントがあるようです。どのような特徴があるでしょうか。Geminiに聞いてみましょう。
ところどころ参加率の低いイベントがあるようです。参加率の低いイベントの特徴を調べるためにはどうすればよいですか?聞いてみると、以下のようにGeminiは参加率の低いイベントを列挙しつつその共通点を解説しました。
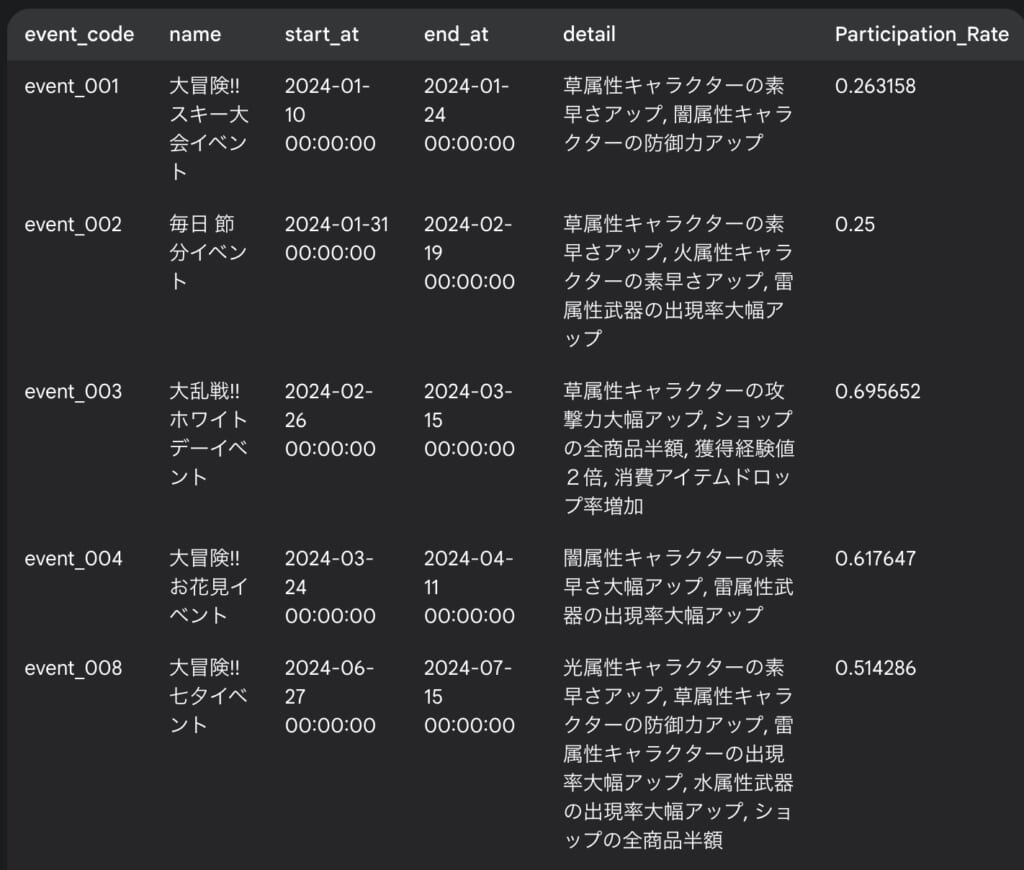

共通点だけ見れば確かにその通り、「特定のキャラクター属性や武器属性に焦点を当てている」「ショップの割引や経験値ブーストなどのボーナス」は参加率の低いイベントに含まれています。しかしながら参加率の高いイベントも同様の特徴を持っています。そうなると、これらの特徴だけで単純に参加率が低いとは確定できません。もっと具体的な数値が必要です。
特徴量エンジニアリング
というわけでGeminiに対して特徴量エンジニアリングを指示しましょう。今回はイベントのdetailカラムに対してワンホットエンコーディングを行い、参加率に対する相関を出力します。ワンホットエンコーディングについてはGoogle Developersで詳細に解説されています。以下のプロンプトを実行します。
event_masterのdetailには開催イベントの内容をカンマ区切りで入力しています。このイベント内容についてワンホットエンコーディングしてください。そのうえで、各イベントの参加率に対する相関を教えて下さい。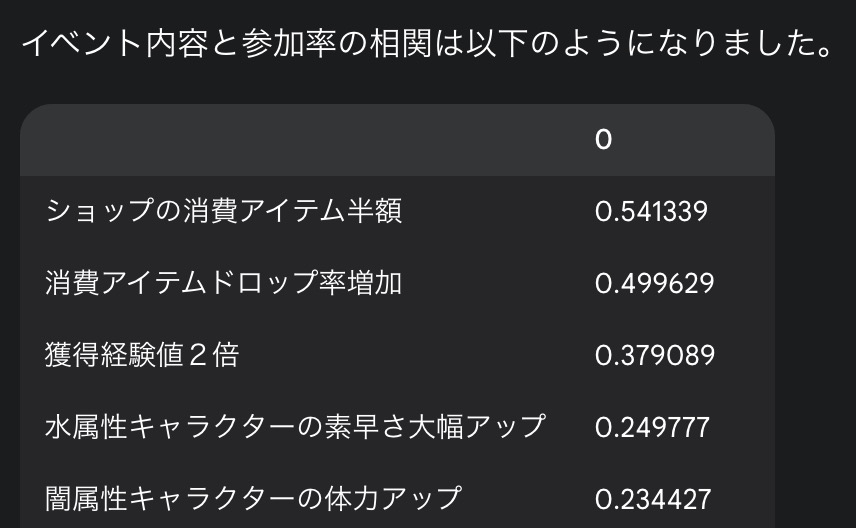

今回は分析に時間がかかったようですが、detail に含まれる特徴と参加率の相関を出力しました。また、その傾向についても解説されています。

(ダミーデータに基づいた結果ですが)これによってどのようなイベントがユーザーに好まれているのかを理解できるようになります。Pythonコードを見るとpandasを使用してワンホットエンコーディングを行っているだけですが、非エンジニアにはなかなか理解が難しいでしょう。問いかけるだけでそれを実行してくれるというのはなかなか素晴らしい機能ですね。
効果測定
さて、実は20回分のイベントには火・水・草・雷・闇・光の6属性のみ入力し、最後の21回目のイベントには新しい”空属性”を追加してあります。これは新たな属性を追加することにより、そのイベントの参加者数や参加率にどのような影響を与えるか、効果測定を行うためです。
| code | name | start_at | end_at | detail |
|---|---|---|---|---|
| event_021 | 春爛漫 新生活応援キャンペーン | 2025-04-26 | 2025-05-12 | 空属性キャラクターの攻撃力大幅アップ, 空属性武器の体力アップ, 空属性武器の攻撃力アップ, 獲得経験値2倍 |
特に詳しい説明はせず、シンプルに以下の質問をしました。
直近で開催された event_021 では新たに "空属性" が追加されました。新たな属性を追加したことで、イベントの参加者数や参加率に対してどのような影響を与えたでしょうか。
Geminiは event_021 の参加率と参加者数を過去のイベントと比較したようです。その結果、参加率が高いことから、新しい空属性の追加はポジティブな影響を与えたと判断できたようです。こういった効果測定にLLMを利用するのは有用な使い方ですね。
次回イベントの提案
LLMの活用方法の一つとして、過去の情報に基づいて新しい提案を生成することが挙げられます。今回のイベントデータ分析においては「次にどんなイベントを開催すればよいのか」という提案が成されると良いでしょう。ユーザーにポジティブな印象を与え続けるようなイベントを企画するのは非常に大変な作業です。そこでGeminiに協力を仰ぎましょう。
これまでの分析を踏まえて、次回 event_022 はどのようなイベントを開催するとよいでしょうか。おすすめを提示してください。
まずGeminiはこれまでの分析を要約しました。

そして要約をもとにして空属性をメインとしたイベントを提案してきました。「ショップの消費アイテム半額、消費アイテムドロップ率増加、獲得経験値2倍などの高参加率に繋がるボーナスを全て盛り込む。」というのは少々欲張りすぎでしょうか。「初心者・復帰勢向けの施策」については重要な項目ですね。

イベント名についても提案がありました。イベント期間や告知方法も重要な検討事項です。
ただし、空属性が好評だったからといって、安易に空属性ばかりを推すのはイベントの流れとして好ましくない可能性もあります。したがって、これらの提案を鵜呑みにするのではなく、効果がありそうな要素をいくつかピックアップして採用するのが賢明でしょう。とはいえ、アップロードしたデータに対して、壁打ちのように質問を繰り返しながら分析を進め、未来の提案を得るという一連の流れは、まさにLLMならではの活用方法と言えるのではないでしょうか。
実はちょっと困ったこと
今回Geminiにアップロードしたcsvは player_data 100件、player_event_logs 4,000件で 合計120KB程度です。実は最初に作成したデータは player_data 500件、player_login_logs 100,000件で 合計3MBほどありました。Geminiの公式ヘルプには、1ファイルあたりの上限が100MBと記載されていたため、合計3MB程度であれば問題ないと判断していました。しかしながら4回ほどのプロンプトでエラーが発生しそれ以降の質問を受け入れてもらえなくなりました。そのため、なんとか120KB程度までデータサイズを削減したところ、今回のすべてのプロンプトを実行できました。アップロードしたファイルに対する分析は、できるだけ1度のプロンプトで完結させる方が良いのかもしれません。
最後に
今回はLLMによるデータ分析を試すためにダミーデータを用意して、いくつかのプロンプトを指示してデータ分析を行いました。MAU等一般的な指標から独自に定義した指標まで、適切に説明すれば理解し、指示した通りのプロットを表示する、という点について非常に役立つ機能だと思います。様々な分析結果から未来を提案させるというのも参考になります。
ただし、最後に述べたように、LLMにはどうしてもデータサイズの制限がある点は考慮すべきでしょう。今回はダミーデータのサイズを切り詰めて対応しましたが、実際に運営しているタイトルのデータを分析しようとしたとき、csvにしても100MBに収まるようなサイズではないでしょう。したがって、大規模なデータを分析する際には、CSVをアップロードするのではなく、直接データベースに対してクエリを実行してもらう方が効率的かもしれません。
そのような場合に活用できる仕組みが、Anthropic社から提案されています。次回、MCPを利用したデータ分析に関して記事をまとめたいと思います。
中村翔吾
ファンカルチャー・デザイン学部
個人でゲーム開発をしている。うさぎ2羽の世話係。






















 Peatix
Peatix Wantedly
Wantedly