

目次
はじめに
AIエバンジェリストの浅田です。
生成AIにおける有用な利用方法の一つにチャットボットがあります。これはお問合せやFAQなどのサイトやサービスにおける補助システムとしても利用されるとともに、LINEなどのメッセージサービスにおいては会話することそのものを目的とする利用法もあります。その際に重要な要素であるキャラクター特性の付与、および記憶の管理技術について考察してみます。
※ 本記事における大規模言語モデルは特に断りを入れない限り、基本的にChatGPTのモデルGPT-4を対象といたします。
大規模言語モデル(Large Language Model以下、LLM)の基本的な概念について
まず、LLMの基本的な仕組みとしてもっともらしい言葉を確率的に出力するモデルであるということがあります。
「もっともらしい」というのは、入力された言葉に続いて出力される可能性が高い言葉を選んでいくということになります。そこで「もっともらしい言葉」の出力をコントロールするためにモデルへの入力、つまりプロンプトが重要となり、それを工夫するプロンプトエンジニアリングの余地が生まれます。
チャットボットにおけるキャラクター特性と記憶の重要性
チャットボットにおいて、ユーザが会話するボットがもつキャラクター特性と記憶は重要な意味を持ちます。それは会話すること自体を目的とするチャットボットであれば顕著です。
チャットボットにおけるキャラクター特性とは大きく以下のようなものになります。
- 言葉遣いや反応などにおける一貫性
- そのキャラクターであれば知っているべきことを知っている
例えば、「ですます調」の口調が、何の前触れもなく急に「である調」に変わってしまったら、ユーザは違和感を感じてしまうので、一貫した口調を維持する必要があるでしょう。もちろん、何かをキーとして口調をあえて変えるというキャラクター特性であれば、それも一つの特性ですが、いずれにしても一貫性を保つ必要があります。
同時に、キャラクターの記憶というのも重要な意味を持ちます
例えば、観光案内をすることができるチャットボットの場合、観光名所の説明をしてほしいと頼まれた時にその情報を知らなければ観光案内をするチャットボットとしての特性がなりたちません。つまり、キャラクター特性を成り立たせる上でも記憶というのは重要なファクターとなります。また、チャットボットとの会話の記憶についても保持することで、ユーザーにとって臨場感のある体験をさせることができ満足度も高まります。
そこで、チャットボットにLLMを利用する上で特性や記憶をどう成り立たせるかということになります。
キャラクター特性の付与について
基本的にLLMにおいて出力をコントロールするためには2種類あります。
- LLMの訓練を行い出力をコントロールする
- プロンプトによるチューニング
LLMの訓練を行い出力をコントロールする
ひとつめは学習データとして会話例のデータを用意し、LLMの学習を行うことで出力をコントロールするという方法です。なお、現時点でChatGPTはgpt-3.5-turboのファインチューニングに対応しています。gpt4については2023年秋に対応予定とのことです(参考)。
- メリット
- LLMの基本的な動作を調整できるのでプロンプトでの調整が減る
- デメリット
- 色々なケースの学習データを用意する難易度や、学習処理や推論を行うためのコストが高い
プロンプトによるチューニング
もう一つの方法がプロンプトによるチューニングです。プロンプトの中に「こういう場合はこういう発言をしてください」という定義をすることで、LLMの出力をコントロールする方法です。
- メリット
- LLMの学習処理など必要なく複数の特性を付与することができる
- デメリット
- プロンプトに定義する内容が多くなるので、プロンプトの長さの限界に左右される
- トークン課金の場合、結果的にAPI利用料金が高くなる
Few Shotプロンプティング
キャラクター特性を定義する時に有用なテクニックとしてFew Shotプロンプティングという手法があります。Few Shot、つまり「いくつかの例」を与えることでLLMの出力をより明確にコントロールするための手法になります。多くの言葉で定義を説明するよりも、例を示したほうがより理解が明確になる、という人間にとっても有効なやり方ではありますが、LLMに対しても効果的な手法として知られています。
これをキャラクター特性の定義にも利用することができます。例えば、テキストでのやりとりをメインとするチャットボットにおいて、「語調・語尾」などは強い特性を表現する材料となりますが、これを明確に定義するのは意外と難しい作業です。
例えば、筆者の出身地である埼玉県には語尾が「だべ/べ」になる方言があります。埼玉県の観光情報を教えてくれるチャットボットの特性にこの方言を付与したいとなったとします。この場合に、語尾に「だべ/べ」を単純に付与するということをやろうとしてもうまくいきません。例えば「夜ご飯を一緒に食べよう」という文言の場合、正しくは「夜ご飯を一緒に食べんべ」となりますが、単純に「べ」をつけるだけだと、「夜ご飯を一緒に食べようべ」となって不自然な表現となります。
そこで、
- 「夜ご飯を一緒に食べよう」は「夜ご飯を一緒に食べんべ」となる
- 「そんなことはないだろう」は「それはないべ」となる
- 「明日は早起きしよう」は「明日は早起きすんべ」となる
といったようないくつかの例を示すことで、言葉で細かく定義するよりも良い結果を得やすくなります。
例えば、
- 「夜ご飯を一緒に食べよう」は「夜ご飯を一緒に食べんべ」となる
- 「そんなことはないだろう」は「それはないべ」となる
- 「明日は早起きしよう」は「明日は早起きすんべ」となる
- 「これはそういうことです」は「これはそうだべ」となる
上記のルールから推測して、以下の文章の語尾を変換してください。可能性が低い変換はしないでください。
#####
そうなんです。このイベントはすごく朝早い時間から始まるから、早起きしないといけませんね。いろんな飲食店も近くにあるので、お昼ご飯も満足できると思います。というようにプロンプトを投げると、
以下の文章に、上記のルールを適用して変換します。
そうだべ。このイベントはすごく朝早い時間から始まるから、早起きすんべ。いろんな飲食店も近くにあるので、お昼ご飯も満足できると思うべ。といった回答を得られます。
記憶の管理
前提としてLLMは構造的には記憶を持ちません。ですが、いくつかのテクニックを使うことで、記憶をもっているように振る舞うことが可能です。
チャットボットにおける記憶は2種類に大別できます。
- チャットボット自身の特性としての記憶
- ユーザーとの会話の記憶
チャットボット自身の特性としての記憶
チャットボット自身の特性としての記憶については、学習処理で持たせることが可能です。例えば、「日本で一番高い山は?」と聞いたら「富士山」と答えるケースなどはLLM自身が持っている記憶をもとに答える例です。現在のChatGPTが広範な知識に対しての記憶を持っているように、幅広い知識を持つことが可能な一方で、学習データの準備の困難さ、学習処理のコストが高くつくという点や、必ずしも学習時の情報に正確に回答するわけでもない(ハルシネーションが発生する)という点も注意が必要です。
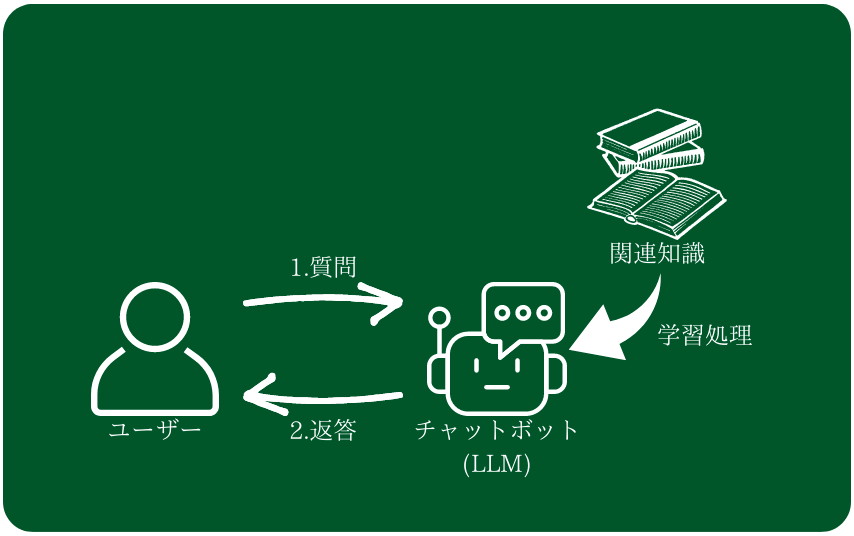
一方で、プロンプトでチューニングすることでも実現が可能です。つまり、知っているべきことを一緒に入力として渡すことで、その知識に基づいて答えさせます。例えば、観光名所を答えるチャットボットであれば、観光名所の情報も与えたうえで答えさせる、というやり方です。学習処理などは必要なく、複数のキャラクターの記憶を持たせやすい一方で、プロンプトの長さの限界に左右されます。

プロンプトの長さに左右されるので、関連知識の情報量が大きすぎた場合に、プロンプトの長さの限界に収まらないという事態が発生します。例えば歴史について答えるチャットボットがあった場合に、すべての時代のすべての場所の歴史について渡すわけにはいきません。そこで、Retrieval Augmented Generationというやり方があります。
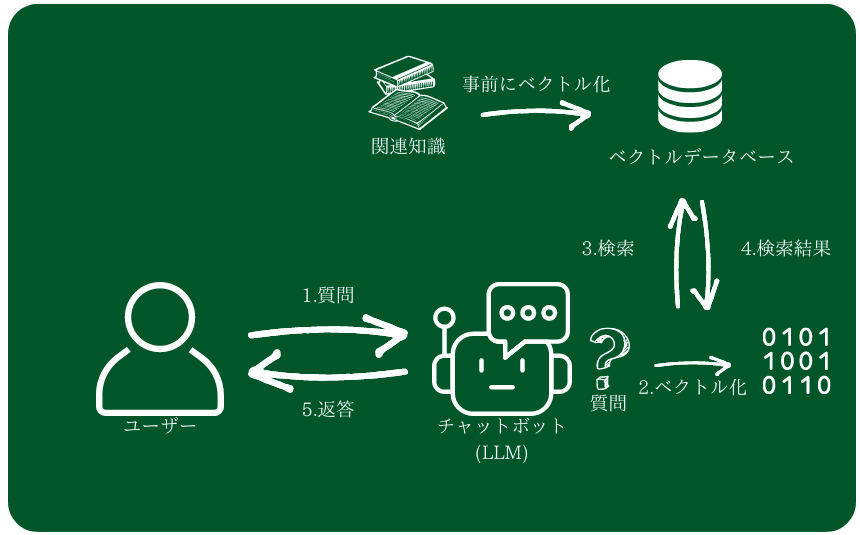
Retrieval Augmented Generation(以下、RAG)
質問に関連する情報だけ取得し(Retrieval)、LLMに情報として追加し(Augmented)、答えを生成する(Generation)という流れになります。
取得すべき情報をどう判定するかについて、いくつかやり方が考えられますが、一般的に行われているのは、ベクトルデータとして検索するやり方です。
- 情報源のテキストデータを細かい単位(チャンク)に分割
- そのチャンクの情報ベクトルを計算
- ベクトルデータベース(ChromaDBなど)に保管
- 質問のテキストのベクトルを計算し、一番関連性の高いチャンクを取得
といった流れになります。OpenAIにも文章のベクトルを計算するAPIは用意されていますし、機械学習の知識が要りますが、独自のベクトル計算の仕組みを利用することもできます。独特な用語を多用するような文章の場合は独自のベクトル計算の仕組みのほうがうまくいくと思います。
ユーザーとの会話の記憶
ユーザーとの会話に関しては、事前の学習処理で持たせることはできないので、プロンプトに一緒に渡してあげる必要があります。そして、「プロンプトに渡す」ということは、プロンプトの長さの限界に左右されるということになります。つまりユーザーとのすべての対話を無限に覚えておくということは現在のLLMにはできません。
先述したRAGに関してはユーザーが明示的に発した発言と関連する可能性が高い情報を返すしくみなので、ユーザーとの会話の中で暗黙的に前提とされる会話の記憶を取得するために利用するのは現実的ではありません。
そこで、また別のテクニックが必要になります。
例えば、
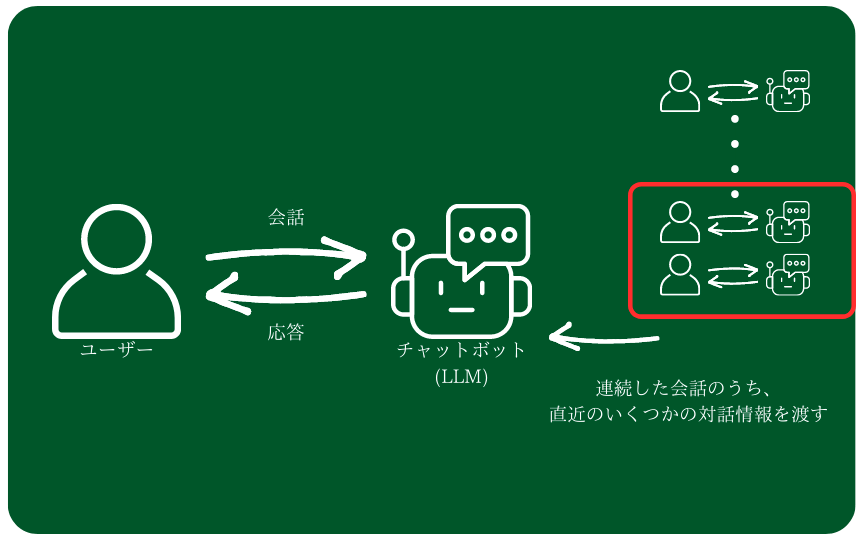
- 直近のいくつかの対話に限定してプロンプトに渡す
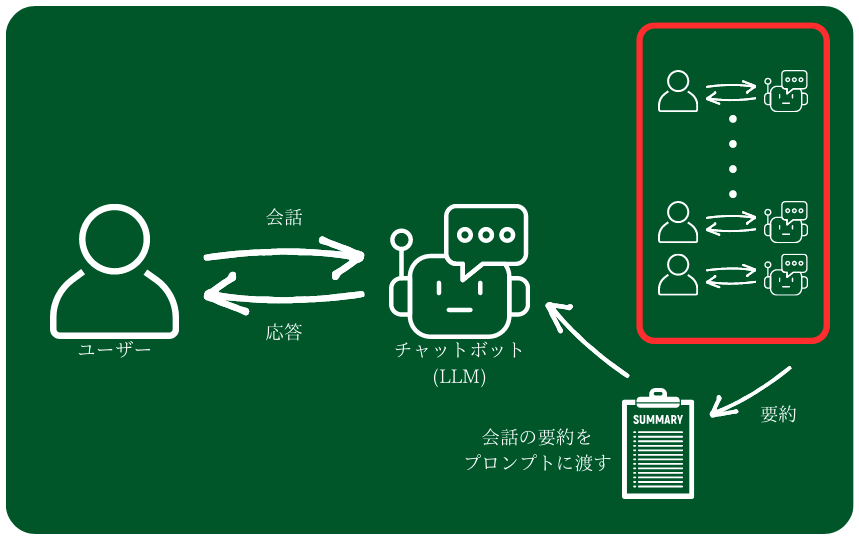
- 要約したものをプロンプトに渡す
というやり方があります。
1つ目は、会話のうち、直近の3個のやりとりに限定してプロンプトに渡して、そのやりとりの記録に基づいた回答をさせるというものです。記憶のディテールを保持したまま、チャットボットにやりとりをさせることができます。欠点としては、ある一定以上前のやりとりは考慮されないことです。
2つ目は、LLM自身を使って会話の要約を行い、それをプロンプトに渡すというやり方です。ディテールは失ってしまうものの時系列的に長期の記憶を保持することが可能です。欠点としては、情報のディテールを保持しづらいという点と、要約の分だけLLMの処理(APIコール)が多くなってしまう、という点になります。
どちらのやり方が適しているかは、実際のアプリケーションの利用傾向などに依存します。例えば、何かを調べるために会話のターンが長くなる傾向があるのであれば、ディテールを失っても長い期間のやりとりを記憶するべきですし、短期的なやりとりの機微を重視するのであれば、短期間のやりとりをディテールを持った形で保持するほうが望ましいかと思います。
おわりに
先述したRAGや、記憶の管理について、LangChainのようなライブラリを使うことで比較的簡単に実装することが可能です。その実装例などは別の機会に記事にできればと思いますが、ChatGPTをはじめとするLLMの飛躍的進歩によって、今まででは考えられなった精度でチャットボットがユーザの意図を理解し、与えらた文脈に沿った自然な返答を返すことが可能になってきました。
サービスのお問い合わせ、FAQといったWebサービスはもちろんのこと、ゲーム内のキャラクターとの対話など、今までは実現するのが困難だったことも可能になってきています。これらのことはユーザにとっての満足度の向上につながると共に、今までにない体験を提供する可能性を秘めています。
そして、プロンプトに入力できる長さの拡大であったり、処理速度の向上、処理リソースの効率化など、LLMの性能があがっていくニュースが日々日々舞い込んできています。LLMの性能はどんどん進化していき、もっといろいろなことができるようになっていくと思うとワクワクしてきますね。























 Peatix
Peatix Wantedly
Wantedly