

我が家のおうさぎ様がルンバをいじめて困っています。ゲームデザイン(GD)部クライアントエンジニアの中村です。
先日「AWS Certified Data Analytics – Specialty」に合格しました。この試験では、AWSのサービスを活用したデータ分析ソリューションの設計、構築、運用、保守の知識があると認定されます。さっそくこの知識を活かしていきたい所存でありますが、まずはダミーデータを使用してAmazon QuickSightでデータ分析をしてみたいと思います。
Amazon QuickSightとは
クラウド向けスケーラブルでサーバーレス、組み込み可能な ML ベースの BI サービス
https://aws.amazon.com/jp/quicksight/
Amazon QuickSightはAmazon Athena、Amazon Redshift、その他データベースなどからデータを取得し、グラフ化できる分析基盤です。インタラクティブなダッシュボードを素早く簡単に構築することができます。データを視覚化することで様々な情報の関係を分析し、ビジネスを向上させることができます。
サーバーレスであるため、サーバーのプロビジョニングやインフラ管理も不要です。分析対象のデータさえ用意すれば簡単に視覚化できます。
さらに機械学習を利用してデータの異常検知や予測を行うことができます。
ダミーデータを用意
ゲームアプリケーションではユーザーが行った様々な行動をログとして出力しています。このユーザー行動ログを分析することで、ユーザーがこのゲームの何に関心を持っているのか、人気のあるキャラクターは誰か、難易度は適切であるか、などを分析することができます。
このユーザー行動ログを収集するためにはAmazon Kinesis Data StreamsやAmazon Kinesis Data Firehoseなどを利用することになりますが、今回はデータの抽出を割愛し「CSV形式のユーザー行動ログがAmazon S3に保管されている」状態から始めます。
さっそくソーシャルゲームを題材として、以下のような「キャラクター獲得ログ」のダミーデータをCSV形式で10,000件生成しました。このデータを視覚化します。
| ユーザーID | キャラクター名 | レア度 | 獲得場所 | 獲得日時 |
| 28 | 織田信長 | 1 | gacha | 2021-11-08 01:09:14 |
| 14 | 前田利家 | 1 | shop | 2021-02-22 05:25:10 |
| 45 | 羽柴秀吉 | 1 | gacha | 2021-10-07 20:02:24 |
Amazon QuickSightでデータの視覚化
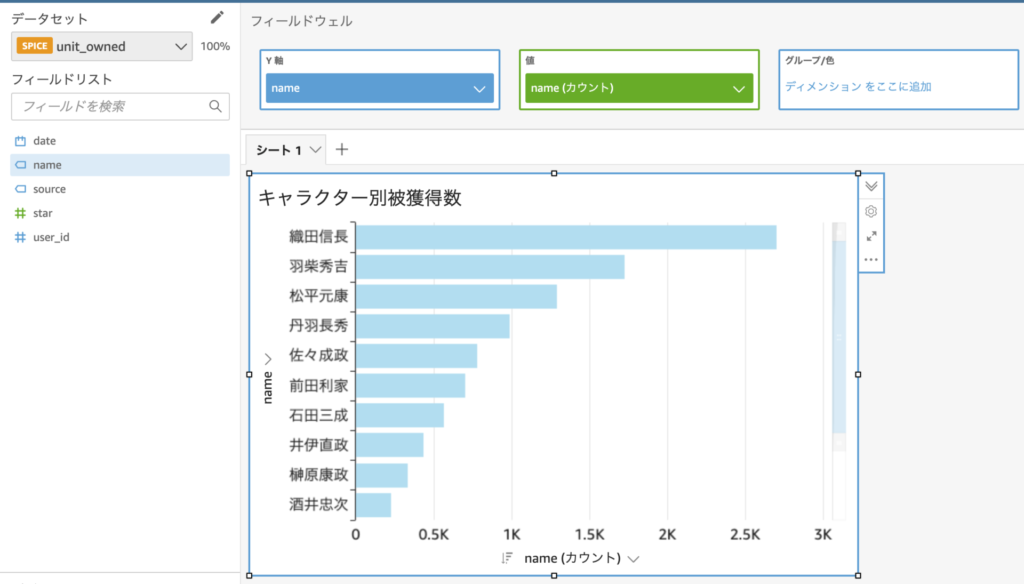
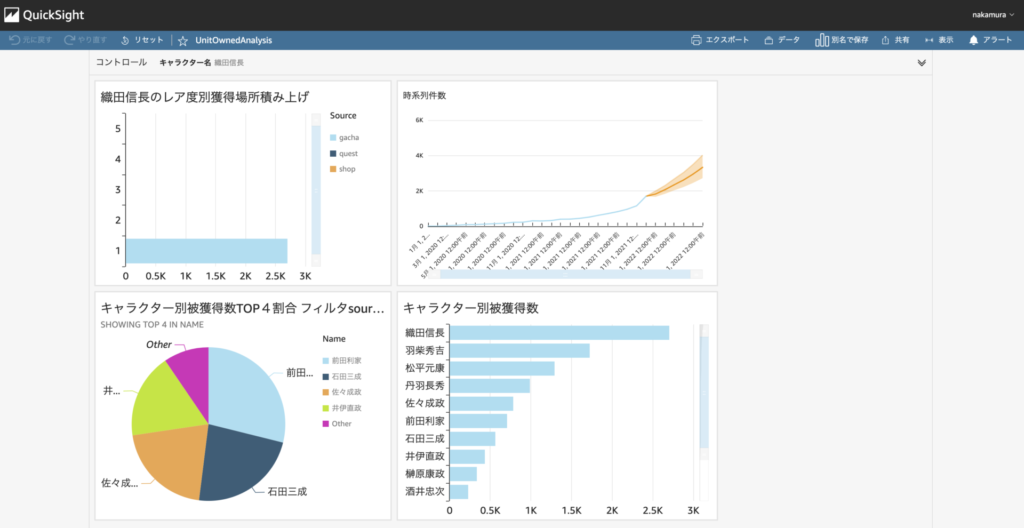
まずは簡単に「キャラクター別被獲得数」を表示してみました。
視覚化で棒グラフを選択し、フィールドウェルにnameフィールドをドラッグアンドドロップするだけで以下の画像のようなグラフを作成することができます。(ランダムなダミーデータですが)織田信長が多くのユーザーに獲得されているようですね。
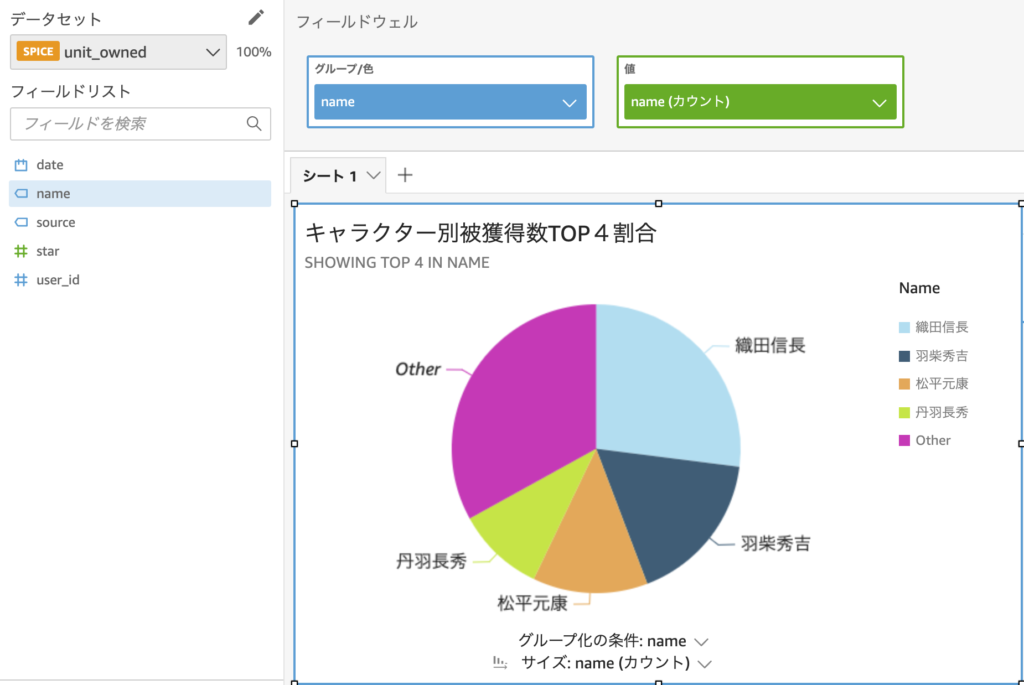
キャラクター別にどの程度獲得されているかがわかったので、その割合を知るために円グラフを生成します。円グラフではすべての情報を表示することはなく、少ない獲得数のキャラクターはOtherにまとめます。これによって以下のようなグラフが出来上がりました。被獲得数TOP4のキャラクターだけで70%近くを占めていることがわかります。
さて、このグラフだけでキャラクター人気を知ることができるでしょうか?
ソーシャルゲームではガチャなどのランダムな獲得方法でキャラクターを手に入れた場合、それは人気であるとは言えません。今回のダミーデータでは獲得場所フィールドを用意しているため、ショップでの獲得に限定したグラフを作れば、ユーザーがわざわざショップで手に入れた人気なキャラクターがわかるでしょう。
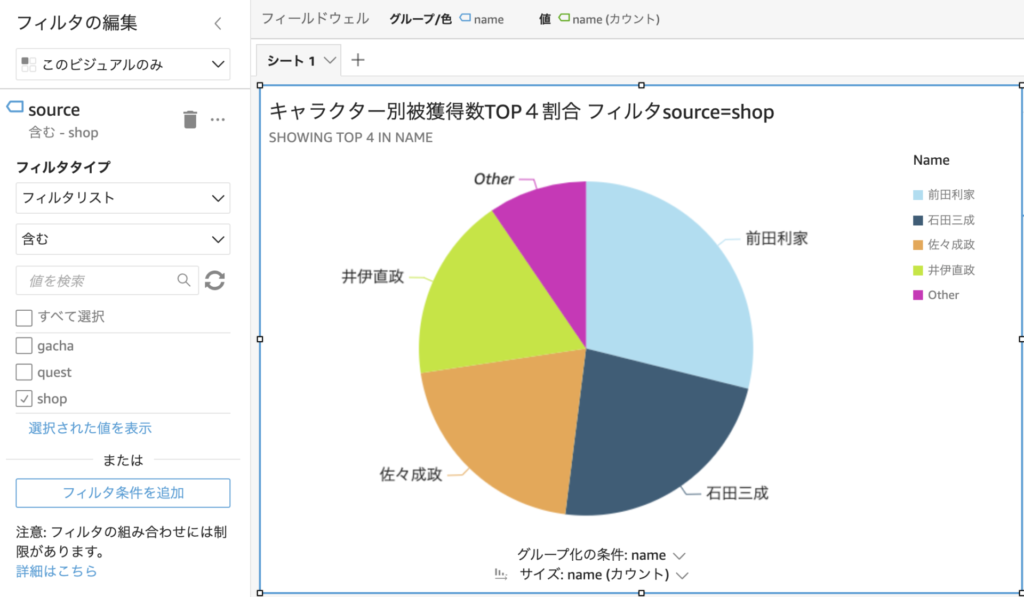
そのためにこの円グラフにフィルターを付けました。獲得場所フィールド(source)をshopに限定したグラフが以下です。これを見ると、被獲得数TOP4のキャラクターである織田信長や羽柴秀吉などは表示されていません。つまり、Shopで購入された人気なキャラクターは異なっているということがわかります。
QuickSightではこうしたフィルターを数クリックで簡単に適用できます。
続いて視覚化ではよく見る時系列折れ線グラフを作成します。
今回のダミーデータでは獲得日時のフィールドがあるので、時系列で変化する獲得件数のグラフを作成しました。ここでは集計単位を”月”にしていますが、簡単に日、週、月、四半期、年の集計単位を切り替えることができます。期間が短い場合は日、週で集計すると見やすいですが、期間が長くなると月や年での集計が見やすくなります。
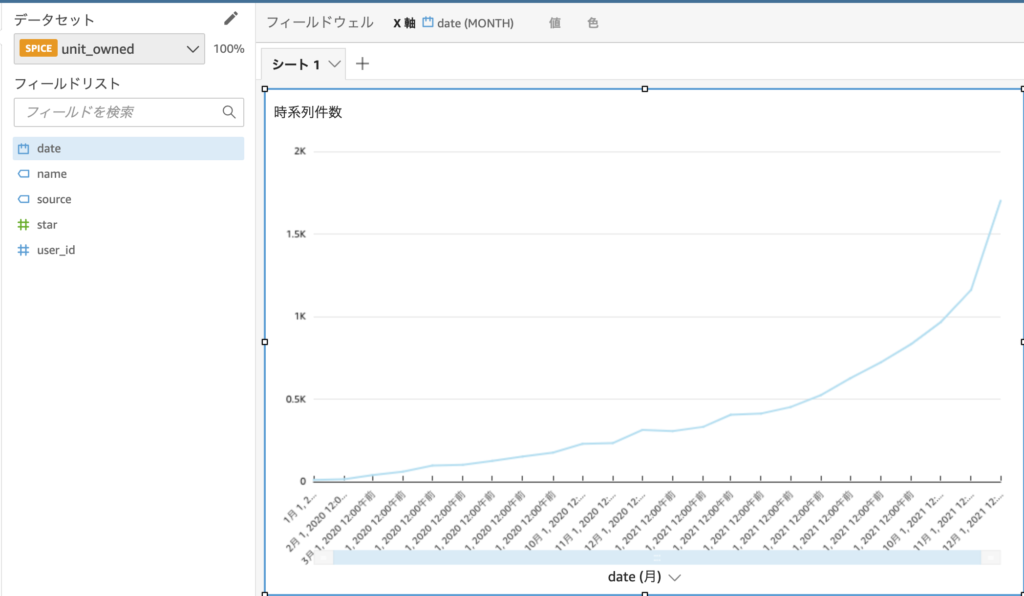
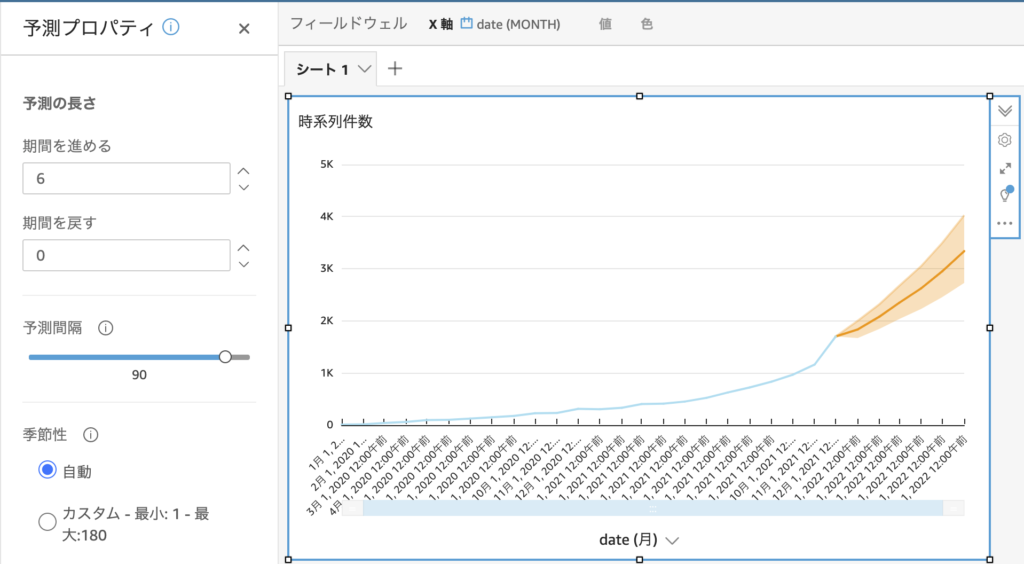
さらに、QuickSightの特徴の1つである「機械学習による予測」を追加します。この予測も、設定画面から「予測を追加」をクリックするだけで以下の図のようなオレンジのラインを簡単に追加できます。
集計されたデータが時系列である場合、今後どのように推移するかは把握しておきたいところだと思います。そのため折れ線グラフを作成したらとりあえず予測を追加しておくと良いでしょう。
最後にパラメータと計算フィールドを試してみます。
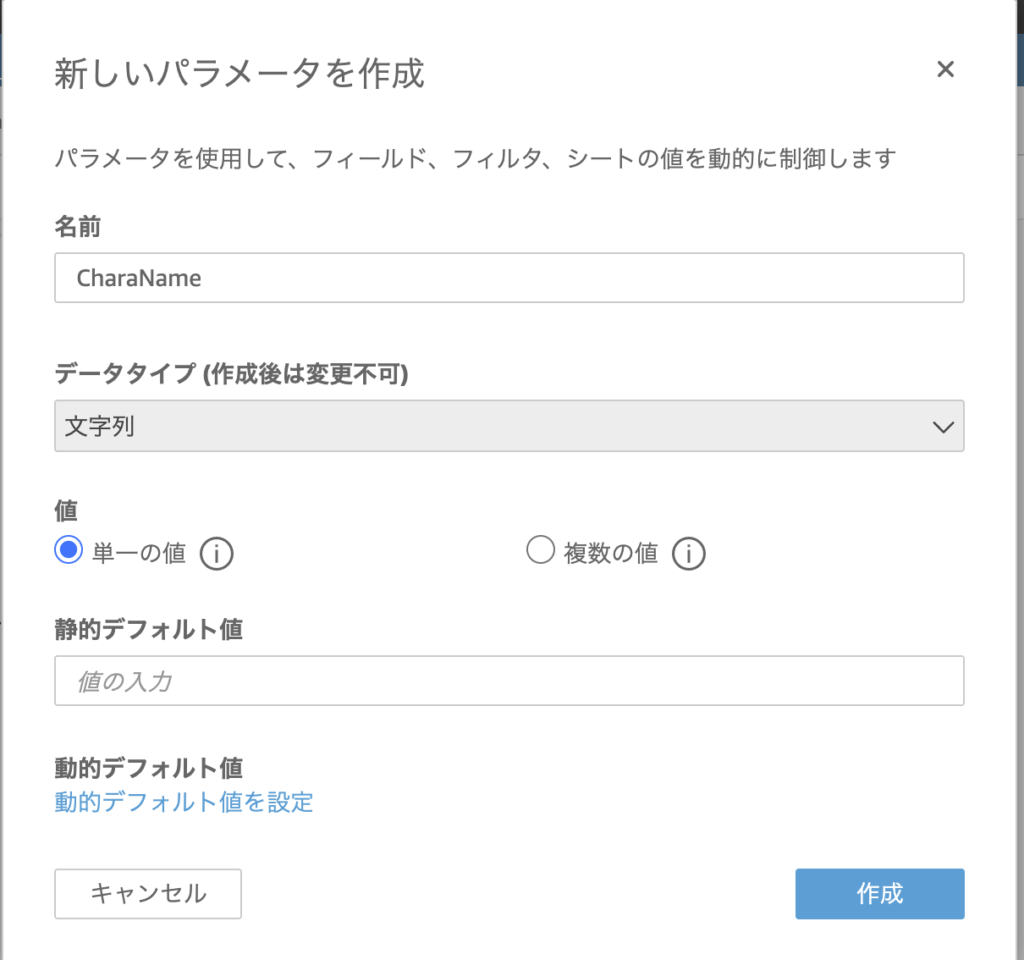
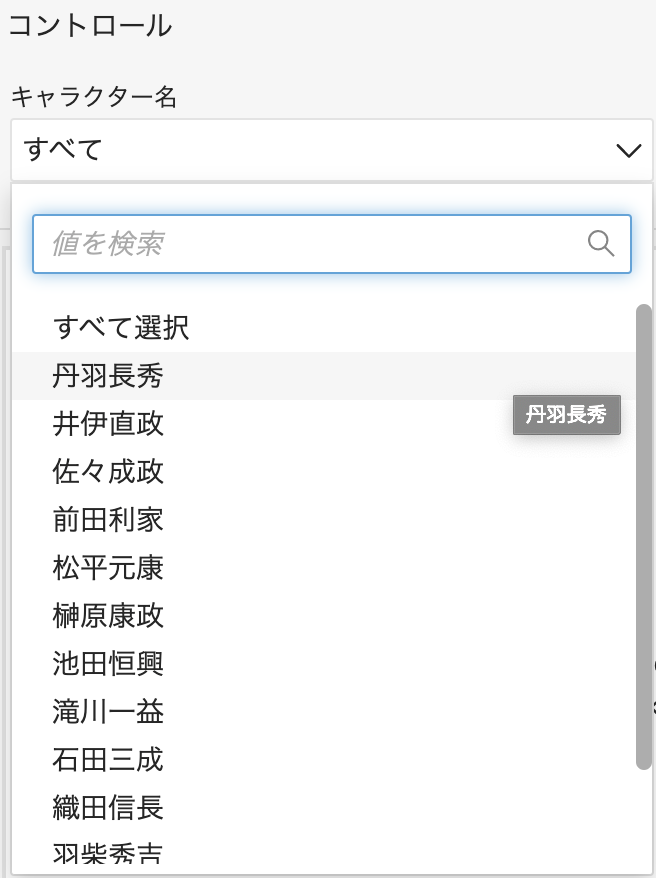
パラメータはQuickSightの可視化をする上で、用意されたデータとは別に利用したい数値や文字列を指定します。今回はキャラクター名をドロップダウンリストにして、特定のキャラクターを選択する機能を追加します。
パラメータの追加も簡単で、「新しいパラメータを追加」から名前とデータタイプを指定するだけです。
そしてこのパラメータをどのように操作するか定義するために「コントロールを追加」します。ここではキャラクター名をドロップダウンで選択させたいのでデータセットからnameフィールドを選択しました。
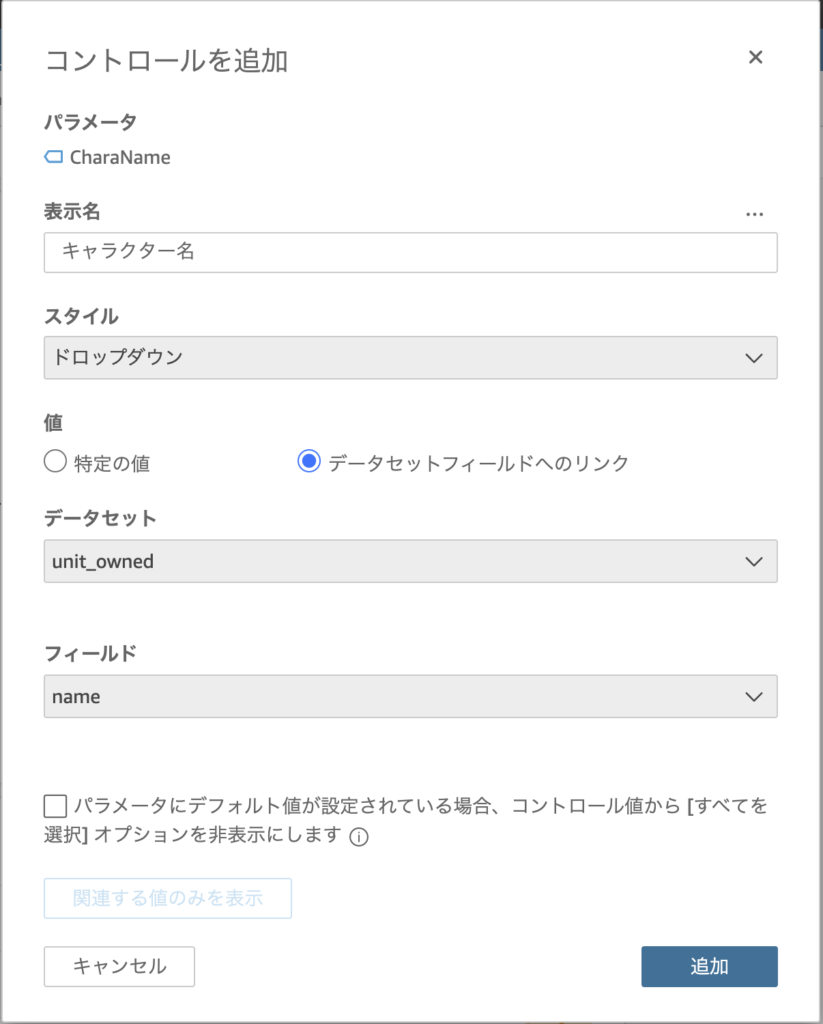
これでQuickSight上でキャラクター名を選択するドロップダウンを表示できました。非常に簡単です。
続いて、計算フィールドは用意されたデータのフィールドとパラメータを組み合わせて、QuickSight上で新しいフィールドを用意する機能です。今回は選択したキャラクター名に該当するレコードにフラグを立てていきます。その場合計算フィールドとして以下のようなコードを記述します。
nameフィールドがパラメータCharaNameと一致する場合に1とする、そうでない場合0とする、新しいIsSelectCharaフィールドを定義しました。
ifelse(name=${CharaName}, 1, 0)これを追加したことにより、ダミーデータは以下のようになります。こうして計算フィールドを追加することにより、用意されたデータをさらに充実させることができます。
| ユーザーID | キャラクター名 | レア度 | 獲得場所 | 獲得日時 | (New)IsSelectChara |
| 28 | 織田信長 | 1 | gacha | 2021-11-08 01:09:14 | 0 |
| 14 | 前田利家 | 1 | shop | 2021-02-22 05:25:10 | 1 |
| 45 | 羽柴秀吉 | 1 | gacha | 2021-10-07 20:02:24 | 0 |
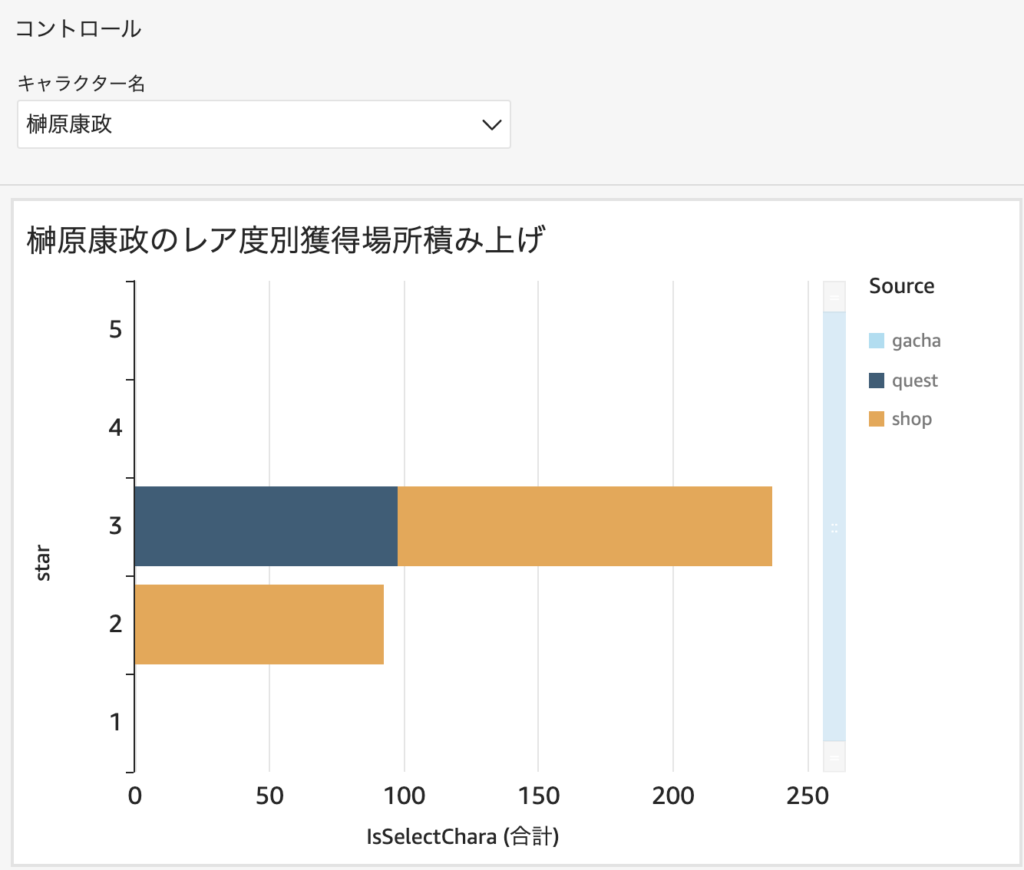
この新しいフィールドを利用して、「選択したキャラクターのレア度別獲得場所」をグラフにしました。
横軸をIsSelectCharaの合計、縦軸をレア度、色分けグループをsourceにすることで、選択したキャラクターがどこから獲得されたか、レア度別に知ることができます。グラフタイトルは <<$CharaName>> を利用することで選択したキャラクター名を表示させています。
このように、パラメータ、計算フィールド、コントロールを駆使することでデータを充実させ、様々な分析が可能となります。事前にどのようなデータ追加を行うか決めておけば、その労力は決して大きくありません。
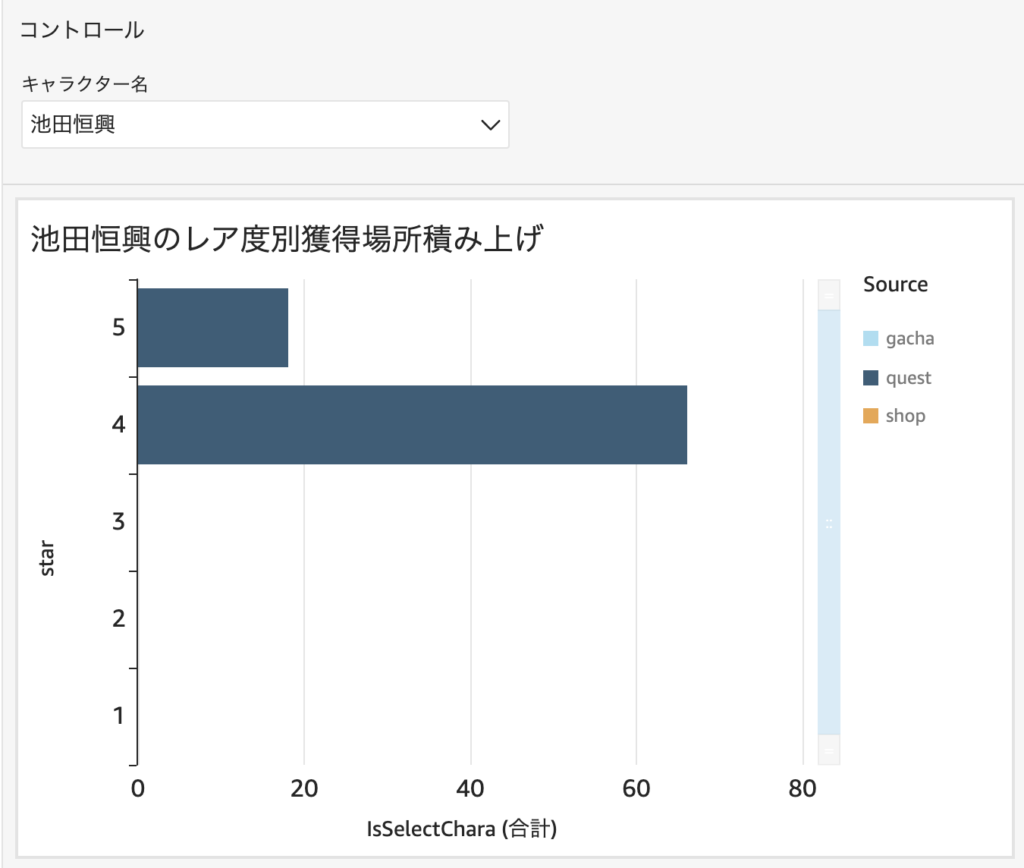
これらの用意したグラフをダッシュボードに公開すれば、プロジェクト内外の関係者とともにデータを見ながらユーザーの動向を分析することができるようになります。
こういった分析は収集するデータや表示するグラフを事前に取り決めておかなければならないため、難易度が高くなります。しかしそんな中でもデータさえ収集してしまえば簡単に可視化できるツールとして非常に良いのではないかと思います。
是非担当案件にも取り入れていきたい所存であります。























 Peatix
Peatix Wantedly
Wantedly