














で用いる図・グラフの特徴とポイント!")

")







の初歩について")






目次
はじめに
AIエバンジェリストの浅田です。
生成AI関連の話題は枚挙に暇がないほど日々出続けています。もはや、日常の風景になりすぎて、ブームという言葉も相応しくないほどかと思います。さて、そんな生成AIですが、どうやって活用すればいいのかよくわからないという方もいらっしゃるかと思います。
そこで、生成AI活用のポイントについて、Amazon Web Services(以後、AWS)の生成AIサービスであるAmazon Bedrock(以後、Bedrock)の利用例を交えて複数回にわたって述べていきたいと思います。なお、様々な種類の生成AIがありますが、主にテキストデータを扱う大規模言語モデルを中心として扱います。特に断りなく生成AIと表記した場合はテキスト系生成AIであるとご理解ください。
もちろん、生成AIの技術はまだまだ発展途上にあると思いますので、ここに書いたことが完全な正解とは限らないとは思いますが、活用する際のなんらかのヒントにしていただければ幸いです。
今回は概要編となります。個々の要素は今後別記事でより深掘りしていく予定です。
生成AIの先祖
生成AIの具体的な活用を考える際に、生成AIのベースとなった技術の理解が重要であると考えます。テキストにおける生成AIといえばChatGPTが有名ですが、これが有名になった2022年ぐらいに突然この技術が生まれたわけではありません。GPTはGenerative Pre-trained Transformerの略称ですが、この名前が示すようにTransformerというAIモデルがベースになっています。現在の多くのテキスト系生成AIもTransformerがベースとなっています。
Transformerは各言語に特化したPre-trained(事前学習)されたモデルを特定のタスク向けに追加学習することによって、それまでの自然言語処理(NLP)におけるベンチマークを塗り替えました。Transformerのモデルが特定のタスク向けに追加訓練を必要としていたのに対し、現在のテキスト系生成AIは追加訓練をすることなく多様なタスクを実行することができる、というのが革命的な点の一つです。
Transformerが得意とする代表的なタスク
そのようなTransformerですが、代表的なタスクに以下のようなものがあります。
- 翻訳
- 与えられた文章を、別の言語に変換する
- テキスト要約
- 与えられた長文から、短い文章の表現に変換する
- 質問応答
- 与えられた文章情報に基づいて、ユーザの質問に対する回答を生成する
- テキスト分類
- 与えられたテキストについて、あらかじめ決められた区分のどれに該当するか分類する
- エンティティ抽出
- 与えられたテキストから、固有情報(名詞、数詞など)を抽出する
翻訳とテキスト要約についてはわかりやすいと思いますが、その他について少し補足します。
質問応答
参考情報となる文章、例えば特定の事実に関して書かれた文章と、それに関する質問事項をセットで入力し、答えとなる文章を生成します。
例えば以下はWikipediaの東京に関する概要部分の引用ですが、
東京は、江戸幕府が置かれていた江戸(えど)という都市が1868年9月(慶応4年7月)に名称変更されたものである。もともと江戸の地には江戸幕府すなわち政府が置かれ、徳川家の人々と老中らが政治を行っており、その一方で京都にも、江戸幕府に日本統治を委任していた朝廷があり、天皇と太政官がいるといった状態の役割分担や二重構造(「複都制的」状態)があった。1869年3月28日に、京都に「都(みやこ)」としての位置付けを残したまま、「東京」に奠都(てんと)された。こうして東京は日本の事実上の首都の役割を担ってきた。このような文章と、「東京の元々の名称はなんですか?」といった質問をモデルに与えてあげて、「江戸(えど)」と答えさせるようなタスクになります。生成AIを利用する際の重要技術となっているRAG(後述)の仕組みと非常に似ています。
テキスト分類
与えれた文章が、あらかじめ決められた区分(クラスとも呼びます)のどれに該当するかを判定させるタスクです。
代表的な例でいえば、SNSや口コミサイトなどにおけるユーザの書き込みを「ポジティブ」、「ネガティブ」、「ニュートラル(どちらとも言えない)」のどれに該当するかを判定する「ネガポジ」判定などがあります。
例えば、
- 東京店でタコスを2つ注文したが最高だった
- 「ポジティブ」と判定
- アメリカへの旅行ツアーのチケットを3人分買ったが、手数料が1000円は普通の相場よりかなり高い
- 「ネガティブ」と判定
- 良いか悪いかは、だいぶ天気に影響されそう
- 「ニュートラル」と判定
といった具合です。少ない量の書き込みであれば人が目で見て判定することも可能ですが、SNSなどの大量の書き込みを分析する際にはこのような技術が役に立つでしょう。
エンティティ抽出
ここでいうエンティティというのは固有名詞や数詞などになります。Named Entitiy Recognition(NER)と呼ばれたりもします。
先ほどの例で説明すると、
- 東京店でタコスを2つ注文したが最高だった
- 「東京」、「タコス」、「2」がエンティティ
- アメリカへの旅行ツアーのチケットを3人分買ったが、手数料が1000円は普通の相場よりかなり高い
- 「アメリカ」、「3人分」、「1000円」がエンティティ
という具合です。
ここで「これが何の役に立つの?」と思われた方もいるかも知れません。エンティティ抽出はこれ単体で役に立つというより、そのほかのタスクと組み合わせて利用することで真価を発揮します。
例えば、先述の「質問応答」の例の際に「東京の元々の名称はなんですか?」という質問の参考情報として、Wikipediaの東京の情報を与えました。ですが、「参考情報をどうやって取ってくるのか?」という問題があります。そこで、「東京」というエンティティが抽出できれば、「東京」というキーワードをもとにWeb検索などで参考情報を取ってくるというアクションが可能になります。
別の例として、オンライン注文システムのチャットボットを考えたときに、「テキスト分類」と「エンティティ」抽出の組み合わせが役に立ちます。先ほどの「テキスト分類」の例ではユーザの書き込みを分類していました。これを以下のように少し変更します。
- タコスを2つ注文したい
- アメリカへの旅行ツアーのチケットを3人分買いたい
- 天気を知りたい
といったユーザの発言とします。オンライン注文システムのチャットボットとしては、以下の2つの情報が必要になります。
- ユーザの意図は何なのか?
- 何かの情報を知りたいのか
- 何かを注文したいのか
- 注文するとしたら何を何個買いたいのか?
- 料理なのか
- 旅行チケットなのか
オンライン注文システムのチャットボットを考えたときに、「天気を知りたい」といったユーザの意図には答えないのが適切でしょう。なので、ユーザの発言が何を意図しているのかを「テキスト分類」において把握し、抽出された「エンティティ(何を、いくつ)」をもとにオンライン注文システムのAPIに対してリクエストを行うことで実際に注文を行うことができます。この仕組みは生成AIにおけるFunction Calling(後述)という仕組みと非常に似ています。
生成AIも同様のタスクが得意、かつお手軽に実行可能
これらのTransformerが得意とする代表的なタスクは、生成AIも得意とするタスクです。そして、前述のように生成AIにおいては追加学習をすることなく上記のタスクをこなすことが可能です。生成AI登場以前は、追加学習を行うプロセスや追加学習のための学習データを用意することも一つのハードルとなっていましたが、生成AIの登場によって、AIによるタスク実行の敷居が、生成AI登場以前とくらべて圧倒的に下がりました。
Transformer時代は英語用のモデル、日本語用のモデル、スペイン語のモデル…といったように各種言語用のモデルが必要でしたが、生成AIは多言語モデルのものが多いです。そのため、英語から日本語、日本語から英語への翻訳などは簡単に実行できます。さらに、既存のAIモデルは「翻訳」と「要約」とは別々のタスクでしたが、生成AIであればその二つを同時に実行できます。英語の文章を与えて、「日本語で要約して」とプロンプトに入力すれば「翻訳」と「要約」を同時に行えます。
日々の業務を分解して考えたときに、これらの生成AIが得意とするタスクを活用できる領域はないかを考えることが生成AI活用の第一歩であると考えます。そして、ビジネスのあらゆる場面で「言語」というインターフェースが使われているので、活用できる場面は必ずあるはずです。
生成AIの真価を発揮させるために
このようにテキストに対するAI利用のハードルを劇的に下げた生成AIですが、一方で生成AIだけの利用ではおのずと限界があります。生成AI単独利用時の課題点として以下のようなものが挙げられます。
- ハルシネーションの低減
- リアルタイムデータ、プライベートデータへの対応
- 現実世界との連携
ハルシネーションの低減
生成AIのデメリットとして色々なところで取り上げられているので、ご存知の方も多いと思いますが、ハルシネーションとは「生成AIがもっともらしい嘘のテキストを生成すること」 です。例えば、先述の「質問応答」の例で言えば、「東京の元々の名称はなんですか?」に対し、「京都」などと回答するなどです。少し知識があれば明らかに嘘だとわかるわけですが、まったく日本のことを知らない人からすると信じてしまってもおかしくないでしょう。
これに対する有効な解決策としてよく用いられるのがRetrieval Augmented Generation(RAG) です。これは「生成AIに対して外部から取得した情報を参考情報として渡してテキストを生成させる手法の総称」です。先述のTransformerが得意とするタスクの「質問応答」と同じように回答の根拠となるべき情報を与えてあげることで、ハルシネーションをかなり低減できることが知られています。
また、RAGに使われたデータをユーザに示すことで、何を根拠とした回答であるかをユーザに示せるというのもRAGを行うメリットの一つです。それによって情報の確認がやりやすくなります。
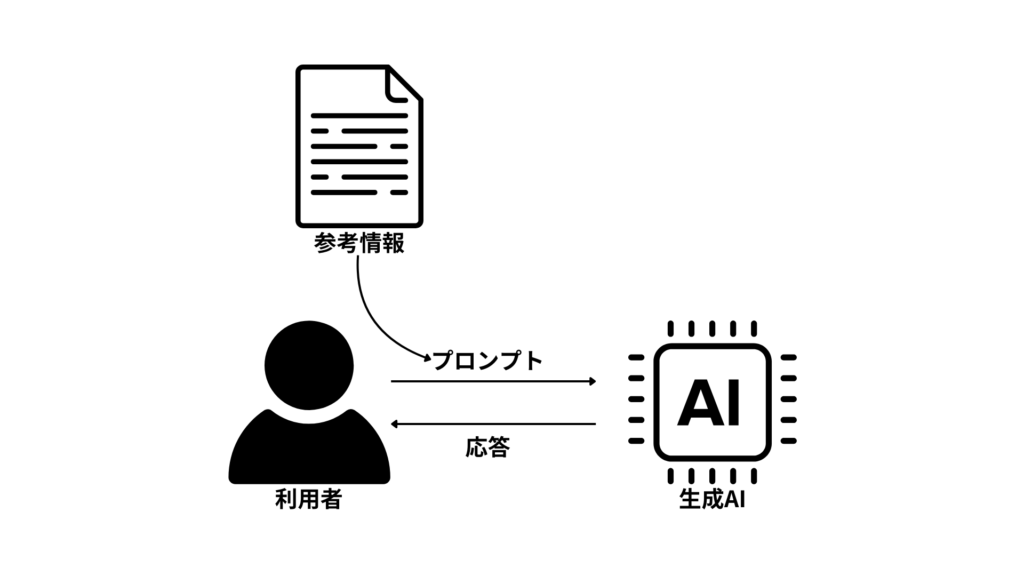
リアルタイムデータ、プライベートデータへの対応
どんな生成AIモデルであっても、過去の時点の限られた情報で学習されています。当然のことながら、学習時に存在しなかった事柄や、学習データに含められなかった事柄に対しては正しく処理できません。そのため、リアルタイムな情報やプライベートな情報を処理するためには、その情報を生成AIに渡してあげる必要が出てきます。
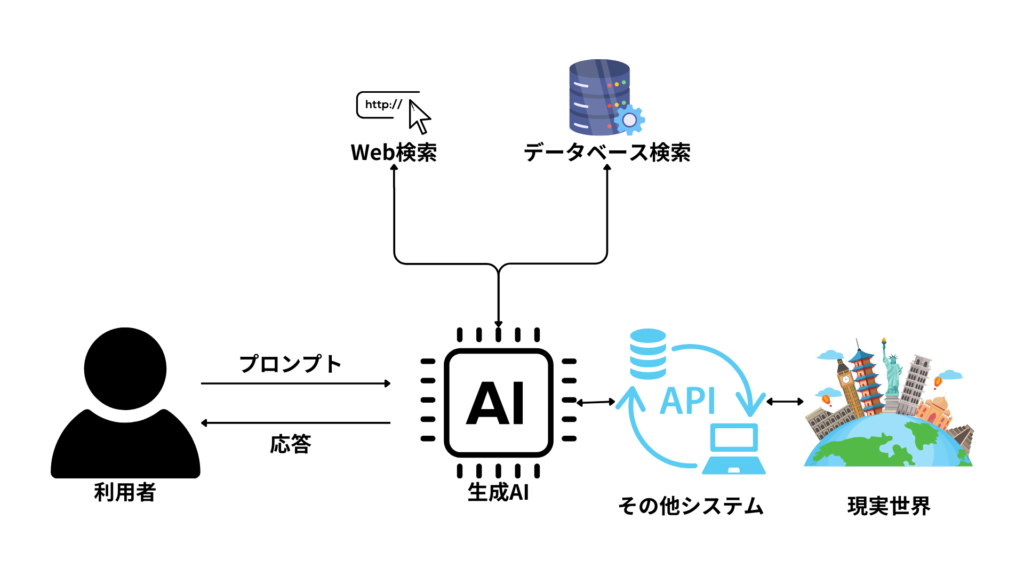
例えば、最新の情報を得るためにWeb検索エンジンを使って情報を取得したり、社内のプライベートな情報を得るために社内のデータベースから情報を取得したりして、その内容に基づいて生成AIに応答を生成させる必要があります。こうすることで生成AIが学習していない最新の情報やプライベートな情報に基づいて処理をさせることが可能になります。

現実世界との連携
生成AI自体は、テキストを入力として別のテキストを出力するツールとみなせます。すなわち、本質的には利用者とのテキスト情報のインタラクションに留まります。それだけでももちろん価値がありますが、現実世界に及ぼす影響はどうしても限定的になります。そこで、生成AIをより活用するために、生成AIにより外部APIの利用を自律的に行わせるAIエージェントという考え方があります。
AIエージェントの肝となる考え方は「どのようなアクションを、どのような情報を使って行うかを生成AI自体に判断させる」ということです。より具体的には、生成AIに対して「使用できるアクション(具体的にはプログラムにおける関数)」と「アクションに必要な情報(関数に与えるべき引数の内容)」を提示して、適切なアクションの判定とそれに付随するパラメータの抽出を行わせます。これは前述のTransformerが得意としたタスクの「テキスト分類」と「エンティティ抽出」の発展系とでもいうべきものです。
例えば、前述のRAGを行う際に、どのようにデータを検索するかという課題があります。利用者の入力に対し、Web検索すべきなのか、データベース検索すべきなのか、そもそも何かを検索すべきではないかの判断がまず必要になります。そして、Web検索やデータベース検索するにしてもどのようなキーワードを使えばいいかの判断も必要になります。このような判断を生成AI自体にやらせるのがAIエージェントの発想です。
これによって、生成AIはテキストを処理する役割を超えて、ITシステムの頭脳としての役割を果たすことができるようになります。
なお、このような機能はAmazon Bedrockで使用できるClaude3などの生成AIモデルではFunction Callingという名前で機能化されています。機能化されていないモデルであっても、プロンプトやファインチューニング(追加学習処理) によって対応することができます。
生成AI活用におけるAmazon Bedrockのメリット
生成AI活用における前述の課題を考えたときに、Amazon Bedrock自身が持つ、以下のような機能は生成AI活用におけるメリットになります。
- 豊富な生成AIモデル
- RAGのためのナレッジベース機能
- AIエージェント機能
- ファインチューニングによるモデルのカスタマイズ機能
さらに、生成AIの真価を発揮させるためには、生成AIのモデルやプロンプトだけでなく、 RAGの情報源となるデータ、連携する対象としてのシステムが重要になります。既にAWS上でビジネスにおけるシステムが稼働しているのであれば、データがAWSに既に存在することが多いでしょうし、既存のシステムと連携するという意味でも、生成AIをAWS上で稼働させることができるBedrockを利用することはメリットが多いと思います。
つまり、生成AIの活用のためのシステムインテグレーションをする上でも、Amazon Bedrockは便利なツールとなります。
さいごに
本記事で述べたことを端的に書くと、以下のようになります。
- 現在の多くの生成AIのベースとなっているTransformerが得意としたタスクを生成AIも得意としており、そこに活用法のヒントがある
- 生成AIの真価を発揮させるためには、データやITシステムとの連携が重要である
- Amazon Bedrockはそのための強い武器となる
次回以降では、個々の要素について深掘りしていきたいと思います。







から、JSONデータをHTTP送信してみよう。")




