

はじめに
デジタルイノベーション部の浅田です。
この記事もそうですが、現代社会では何か文章を書くということを老若男女問わず多くの人が行なっているかと思います。記事といった形式張った形ではなくとも、SNSへの書き込みであったり、メールの文章、チャットでのやりとりなど、現代社会では至るところで文章が生成されています。
このような文章、すなわちテキストデータから、何かしらの知見を得ようという試みはテキストマイニングと呼ばれますが、その時に使われる技術が自然言語処理(Natural Language Proccessing、以下NLP)という技術です。
そのNLPを構成する一つの要素に、固有表現抽出(Named Entity Recognition、以下NER)というものがあります。
そして、AWSで固有表現抽出のサービスを提供するのがAmazon Comprehend(以下、Comprehend)というサービスになります。
そこで、固有表現抽出とはどのようなもので、何がうれしいのかをご紹介します。そしてComprehendを使うことで簡単に固有表現抽出を活用できることをご紹介したいと思います
NER(固有表現抽出)とは何か
そのままですが、固有表現(Named Entity)を抽出(Recognition)する処理ということになります。固有表現とは何かというと、大雑把に言えば固有名詞です。
例えば「国家」は一般名詞(Entity)であり、「日本」は固有名詞(Named Entity)です。同様に、「組織」は一般名詞であり、「アマゾン」は固有名詞です。
このように、「日本」という単語が「国家」というカテゴリの特定のものを表現していると認識する処理が固有表現抽出ということになります。
ただ、注意していただきたいのは、特定の物体だけでなく、「日時」といったものも固有表現に含まれます。なので、「2021/12/03」という表現が、時間一般の特定時点の表現であるということを認識するのも固有表現抽出です。同様に「42」という数値も、数値一般の特定表現として認識するのも固有表現抽出のタスクです。
NERができると何がうれしいのか
例えば、
- 色々なドキュメントを整理してナレッジを得る目的で多数のドキュメントから特定の組織に関する文を抜き出したい
- チャットボットに対するユーザの発言から、ユーザが購入しようとしている製品名を抜き出したい。
上記のようなケースで組織名や製品名の判定にNERが役立ちます。
同様のことを「正規表現でやれるのではないか」と思った方がいるかもしれません。実際、Pythonの自然言語処理ライブラリであるspacyでは、正規表現のパターンを使って固有表現抽出を行うような機能もあります。
ただ、いくつかのケースにおいては正規表現だけではうまくいきません。
例えば、ドキュメントから「アマゾン」という組織名を探し出したいとします。その時にドキュメント内に組織名としての「アマゾン」と熱帯雨林の「アマゾン」との記述が混在していた場合、正規表現ではうまくいきません。この場合、組織としてのアマゾンと地名としてのアマゾンを文脈から区別する必要があるためです。
そして、それを行うことができるAWSのマネージドサービスがComprehendになります。
Comprehendの主要機能
2021/12現在、Comprehendができることをあげると、以下のようなものがあります。
- 固有表現抽出
- キーフレーズの検出
- 使用言語判定
- 個人情報識別(英語のみ)
- 感情判定
- 構文解析(日本語未対応)
- トピックモデリング
今回は、固有表現抽出に絞って、ご紹介します。
Comprehendで固有表現抽出をしてみる
Comprehendには、GUI上で機能を試すための画面が存在します。
東京リージョンのReal-time analysisの画面にアクセスすると、以下のような画面が表示されます。
ここのInput textとなっているテキストボックスに「我々はアマゾンの奥地に踏み入った」という文章を入力して、Analyzeのボタンを押します。
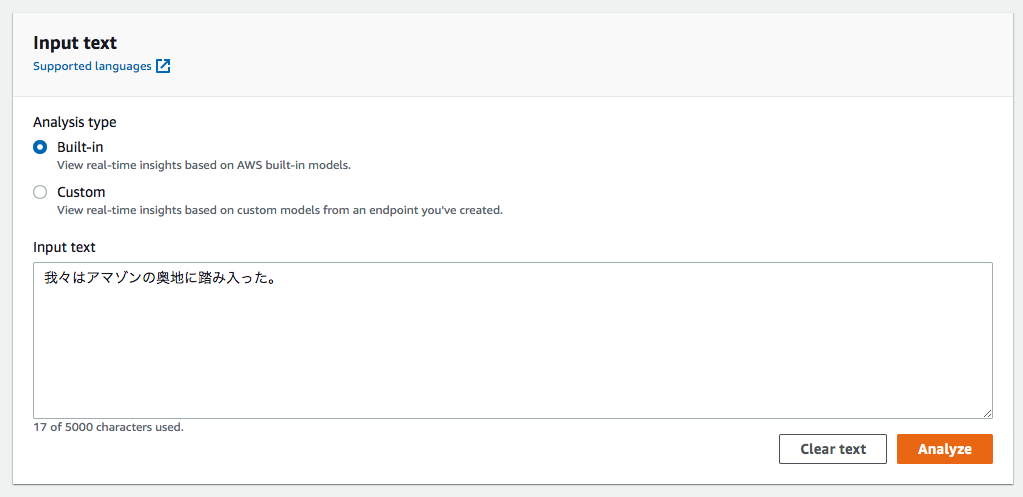
すると以下のような解析結果が得られます。
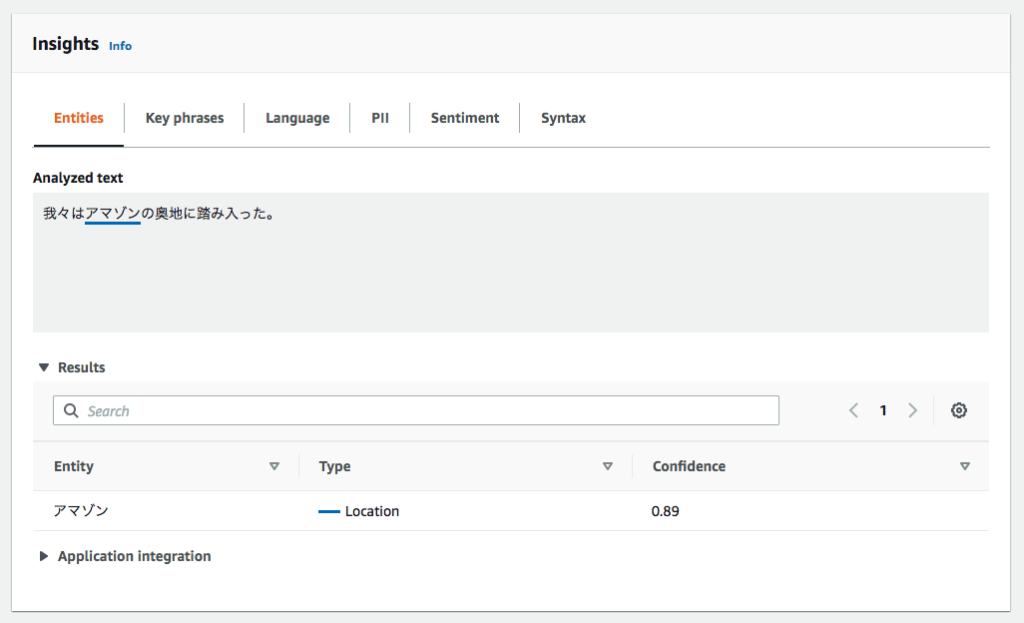
アマゾンがLocation(場所)のエンティティタイプとして抽出されました。
もちろん、CLIなどでも実行できます。
今回は文章として、「アマゾンはワシントン州シアトルに本拠がある」を指定して実行してみます。
aws comprehend batch-detect-entities --text-list アマゾンはワシントン州シアトルに本拠がある --language-code ja上記コマンドを実行すると、以下のような結果が得られます。
{
"ResultList": [
{
"Index": 0,
"Entities": [
{
"Score": 0.9488572478294373,
"Type": "ORGANIZATION",
"Text": "アマゾン",
"BeginOffset": 0,
"EndOffset": 4
},
{
"Score": 0.923648476600647,
"Type": "LOCATION",
"Text": "ワシントン州シアトル",
"BeginOffset": 5,
"EndOffset": 15
}
]
}
],
"ErrorList": []
}今回のアマゾンはORGANIZATION(組織)として認識されています。
このように、Comprehendを利用することで簡単に固有表現抽出を行うことができます。
おまけ
Comprehendをカスタマイズ
便利なComprehendですが、一般的なエンティティは識別できるものの、ドメインによっては不十分な場合があります。そのようなケースのために、Comprehendには固有表現抽出を追加で学習させる機能があります。
学習させるにあたって2つのタイプの学習方法を選べます。
- 認識させたい固有表現を含む/含まないテキストデータを用意するとともに、その文のどこにどんな固有表現があるのかを明示したデータ(アノテーションデータ)を用意
- 認識させたい固有表現のリストと、その固有表現を使用した/使用していないテキストデータ(未アノテーションデータ)
1の方法は、文章中の固有表現の位置を明示(アノテーション)するので、手間はかかりますが、2のデータよりも正確な認識能力を期待できます。
ただし、残念ながら現時点でComprehendのカスタマイズは日本語には対応していません。今後に期待です。なので、以下は今後Comprehendのカスタマイズに対応した場合に役立つ情報としてご参照ください。英語は対応していますので、以下の情報は英語のモデルをカスタマイズする際にも、もちろん有用なやり方となります。
Amazon SageMaker Ground Truthによるアノテーションの省力化
1,2の方法ともに、データはより多くあれば、学習されたモデルの性能も期待できるものになりますが、特に1の場合は文章中の位置まで情報を付与しなければいけないので、手間がかかります。
そんな時に使えるAWSのサービスが[Amazon SageMaker Ground Truth](Amazon SageMaker Ground Truth | AWS(以下、Ground Truth)です。
教師ありの機械学習を行う際には大量の正解データが必要となりますが、Ground Truthは、それをサポートするサービスです。
画像データの分類や検出、テキストデータの分類などとともに、NER用のアノテーションもサポートしています。
大枠の流れとしては、以下のようになります。
- 未アノテーションのデータを用意する
- アノテーションを行う要素を定義する
- アノテーションを行う主体を指定する
- ジョブをアノテーション実行者に割り当てる
ここでは上記のうち2と3が特徴的です。
2についてですが、Ground Truthはインフラストラクチャを気にすることなく、アノテーションのためのGUIを提供します。素で行おうとすると、サーバを起動したり、ユーザを認証したり、アノテーションのGUIや処理ロジックを作成したり、アノテーションデータを保存したり、といった一連の流れを用意しなければいけません。Grountd Truthであれば、どういうデータをどのようにアノテーションさせたいかを指定するだけで、全部面倒をみてくれます。
そして、Ground Truthの面白い点が3です。機械学習に使用するためのアノテーションは人力で行うわけですが、Ground Truthは行う主体を以下の3種類から選べます。
- 社内の人間やパートナーなど限られたプライベートメンバ
- AWS Marketplace で利用可能なサードパーティベンダ
- Amazon Mechanical Turk を利用したクラウドソーシング
面白いのは2,3で、データの機密性やコストなどの問題が許せば、人的リソースもスケーリングすることができるということです。専門性が要求されるようなタスクはその知識を持ったサードパーティのベンダがいればそこに任せるという選択肢も取れます。
Ground Truthの実行画面サンプル
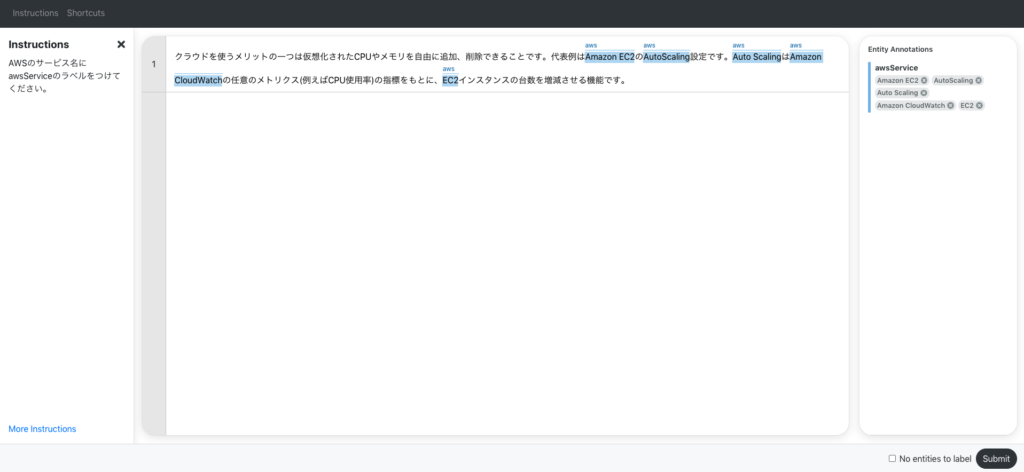
上記は、Ground Truthの画面ですが、このようなインターフェースをGround Truth側が用意してくれるので、タスクを割り当てられたメンバは画面上からポチポチするだけで、NERのデータをアノテーションすることができます。
繰り返しますが、現時点では残念ながらComprehendは日本語のカスタマイズモデルは対応していません。なので、実際にGround TruthとComprehendを組み合わせるとすれば、英語などのカスタマイズモデルを作成する場合に限られます。現時点では、日本語のアノテーションされたデータの利用用途はComprehend以外の言語モデルのトレーニング(例えば、SageMakerで独自のモデルをトレーニングするなど)になってしまいますが、Comprehendが日本語のカスタマイズモデルに対応すれば、あまり自然言語処理知識に詳しくない場合でも一般的でない独自ドメインでもNERが利用できるなど、利用用途が大きく広がると思います。対応が待ち遠しいですね。
終わりに
以上、NERとは何か、NERができると何がうれしいのか、そして、Comprehendを使えば簡単にNERを実施できるということを見てきました。
実際自前で、NERを実装しようとすると、データの準備に始まって形態素解析であったり、単語のトークン化、学習処理など自然言語処理や機械学習の知識を求められます。
一般的な用途であれば、Comprehendを利用することで、お手軽に機械学習のテクノロジーを利用した自然言語処理の恩恵を得ることができます。また、現時点では英語などの一部の言語にはなってしまいますがカスタマイズも可能で、Ground Truthを利用すればデータのアノテーションも、マネージドな形で省力化して実施することができます。
皆様のテキストマイニングライフの一助になれば幸いです。
参考リンク
Amazon Comprehend を使用してカスタムエンティティレコグナイザーを構築する
Developing NER models with Amazon SageMaker Ground Truth and Amazon Comprehend























 Peatix
Peatix Wantedly
Wantedly