

目次
はじめに
クラウドインテグレーション部の浅田です。
OpenAIが提供しているChatGPTが話題になっていますね。3月に入りAPIの提供も始まったので、色々なサービスへの利用が考えられ始めてます。今回はアノテーションをサポートするツールをプライベートで作ってPoC(Proof of Concept)をした話を通して、ChatGPTの魅力や性能について書いていきたいと思います。
※ここでいうアノテーションとは、機械学習の分野で「教師あり学習を行うためにデータに対してラベルづけする行為」を指します。
想定する読者
- ChatGPTってどんなものか知りたいかた
- ChatGPTってどうやって使うのか知りたいかた
ChatGPTについて
ChatGPTはOpenAIが作った大規模言語モデルです。自然な会話でのやり取りをできるというのが最大の魅力で、自然な文章を生成することができます。
最近まではブラウザでのみアクセスが可能だったのですが、3月に入りAPIの提供が始まったことで、アプリケーションから利用することが可能になり、様々な製品への応用が始まっています。
ChatGPTができること
ChatGPTができることを一言で表すなら「対話ができる」ということです。そして、対話ができるということは「言われたことを理解し状況に応じた発言ができる」ということでもあります。
突き詰めれば、ChatGPTができることはそれだけのことですが、膨大なデータでトレーニングされていることで、様々な応用がききます。
アノテーションについて
ChatGPTをはじめとした機械学習モデルは、教師データを与えることによって学習されます。例えば文章の感情判定モデルで、ポジティブ(な感情)とネガティブ(な感情)を識別したいモデルを作りたければポジティブな文章データやネガティブが文章データをたくさん用意することになります。
教師データとして使用する際にはそれぞれの文章がポジティブに属するのか、ポジティブに属するのかという情報を紐づけて与えてあげる必要があります。一方でポジティブ、ネガティブな文章は世界中にたくさんあると思いますが、ポジティブな文章である、ネガティブな文章であるという情報とセットで管理されていることは少ないので、データ自体と、それの情報を紐づけてあげる必要ががあり、その作業がアノテーションと呼ばれる作業になります。
アノテーションの課題
アノテーションは基本的には人手で行うことになりますが、大量のデータを作成するには人的コスト、時間的コスト、結果的には金銭コストが掛かってきます。そこで、ChatGPTを利用することでテキスト情報のアノテーションを手伝ってもらおう、というのが今回のコンセプトになります。
今回のツールのつくり
ユーザはWebブラウザ上から、アノテーションしたいテキストを一行ごとに記載したファイルをアップロードし、その際にアノテーションしたラベルの内容(先述の例であれば、「ポジティブ」、「ネガティブ」など)を指定することで、ChatGPTがそれぞれのテキストごとにラベルづけし、その理由、および確信度を表示する、という内容になります。
画面イメージとしては以下です。
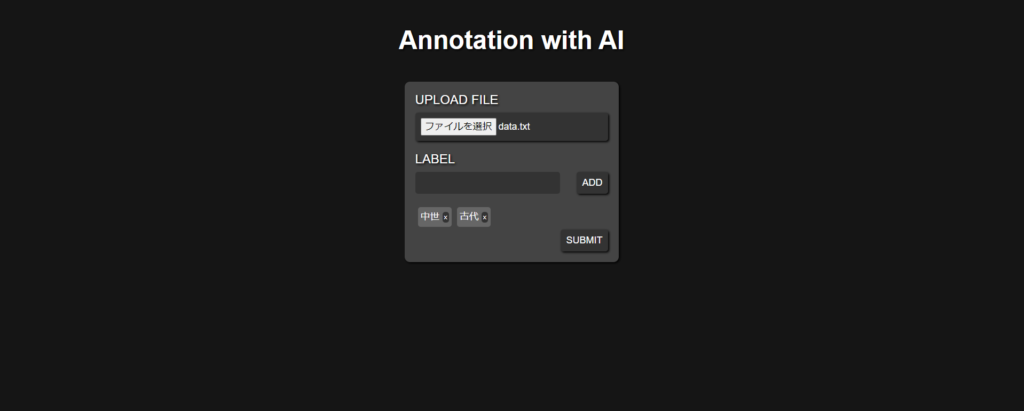
テキストファイルを選択し、タグを指定すると、その結果が表示されるといった形になります。
今回のテキストファイルの中身は以下の様になっています。
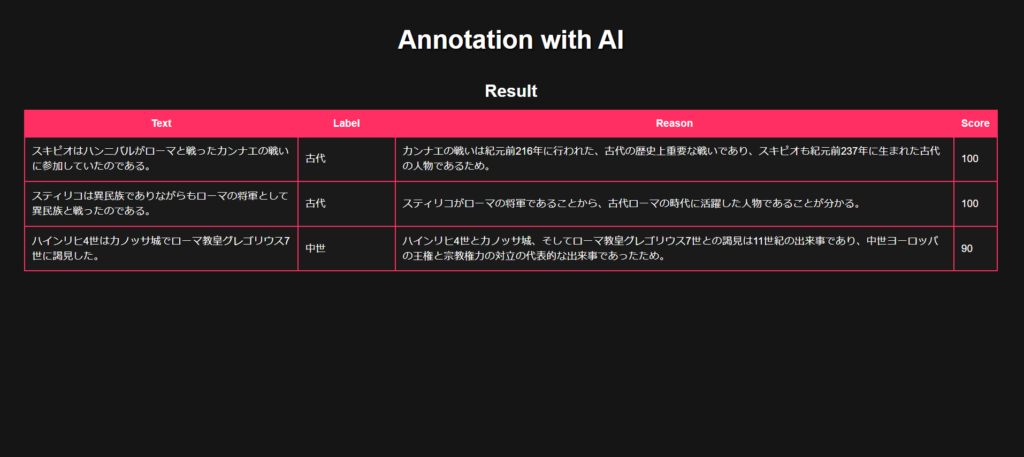
スキピオはハンニバルがローマと戦ったカンナエの戦いに参加していたのである。
スティリコは異民族でありながらもローマの将軍として異民族と戦ったのである。
ハインリヒ4世はカノッサ城でローマ教皇グレゴリウス7世に謁見した。それに対し、古代か中世でラベルを指定して実行した結果が上記の結果画面になります。適切にラベリングされていますね。
Reason列には、ラベル付の理由も具体的に書かれており、また歴史的事実とも合致しておりChatGPTのテキスト生成能力の高さが感じられる結果となりました。
ChatGPTのAPIを使う上でのポイント
フロント用のReactコード、およびバックエンドのChaliceのコードは以下のリポジトリで公開しています。
(ちなみに、annot”a”tionがannot”ai”tionになっているのは意図的です)
作り自体はシンプルなので、説明は割愛させていただきますが、ChatGPTのAPIの部分だけ補足させていただきます。
冒頭で、ChatGPTができることは「対話ができる」、すなわち「言われたことを理解し状況に応じた発言ができる」と述べました。裏を返せば、「いかにChatGPTにこちらが意図していることを伝えるか」が重要なポイントとなってきます。
機械学習の世界には雑なデータで作ったモデルは雑な結果しか生まないという意味の「Garbage In, Garbage Out」という言葉がありますが、ChatGPTでは雑な質問は雑な返答しか生まないといってもよいでしょう。
つまり、ChatGPTに対してどのような言葉を投げかけるかを設計することが、ChatGPTを上手く使うポイントになります。これはプロンプトエンジニアリングとも呼ばれます。
今回であれば、以下のようなプロンプト(発言)をユーザの入力を埋め込んで作成しています。
textには入力ファイルの1行が、labelsには指定したラベル(先述の例であれば”ポジティブ,ネガティブ”)が入ります。
{text}
上記の文章について、ラベルづけしてください。
答えは{labels}のいずれかで答えてください。
また、以下のフォーマットに従ってください。
ラベル:○○
理由:△△
確信度:□□
○○には{labels}のいずれかを入れてください。
△△にはラベルづけの理由を書いてください。
□□にはそのラベルが正しいと思う度合いを0から100の数値で表してください。ポイントは2点です。
- どのようなタスクを実行したいかを明示します。
- 今回であれば「ラベルづけ」でうまくいってますが、端的な言葉でうまくいかない場合は、出きるだけ明示します。例えば、「どの概念に該当するか判定してください」など。
- 出力の形式に対して、できるだけ具体的な制約をかけます。
- フォーマットの指定がない場合でも、結果としては同じような内容を返してくれますが、出力の形式が安定しないのでAPIとして利用する際にはハンドリングしにくくなります。
- 今回の例であれば、何も制約をかけないと「ラベルは「〇〇」です。理由は△△だからです。」であったり、「〇〇。理由は以下です。△△。」など出力が一定の形式にならず、プログラムから利用が難しくなります。
- フォーマットの指定がない場合でも、結果としては同じような内容を返してくれますが、出力の形式が安定しないのでAPIとして利用する際にはハンドリングしにくくなります。
上記により
ラベル:○○
理由:△△
確信度:□□のようにChatGPTの出力をコントロールできるので、プログラム側で正規表現で結果を抜き出すことが容易になります。
なぜChatGPTでアノテーションなのか
上記でみたように、与えたテキストがどのラベルに該当するかを返してくれるというのが今回のツールのコンセプトになります。
これはつまり、テキスト分類のアプリケーションを作っているということでもあります。
そこで疑問が湧く方もいるかもしれません。ChatGPTでテキスト分類ができるなら、アノテーションでデータを用意することなどする必要がないではないか、と。
確かにそれは一面では正しいですが、以下に記述するChatGPTの弱点を考えた時に、独自の機械学習モデルを作成することが必要なケースはまだまだあり、その際にChatGPTによるアノテーションが役に立つかもしれないと考えたためです。
ChatGPTの弱点
テキスト分類機能を実装するにあたり、ChatGPTにテキスト分類をさせれば事足りる可能性は高いと思います。それぐらいChatGPTの性能は驚異的です。
ただ、ChatGPTにもいくつか弱点はあります。
出力の正確さに偏りがある
ChatGPTはあたかも知識に基づいて発言しているように見えますがそうではありません。与えられた文章に続けて出力するとしたら、最も可能性のある(尤もらしい)文字列を出力しているだけです。それだけで、文章として自然で、文意を汲み取ったような文章を出力することは驚嘆すべきことですが、知識に基づいて発言しているわけではないのです。
したがって、学習データの少なさなどにより、連続する文章として可能性の高低を判断しにくい場合、出力を安定させることができません。すなわち、毎回バラバラなことを発言することになります。そして、全く事実と異なることを述べる可能性があります。
欧米の事柄や世界的に見ても有名な出来事や人物についてはかなり正確な記述が作成されますが、ローカルな出来事や人物については断片的で間違った記述をする傾向にあるようです。
これは追加のデータの学習で解決するものと思いますが、今のところ学習処理をユーザ側で行うことはできないので、対処することができません。
学習データにない新しい言葉には対応できない
ChatGPTは、当然のことながら学習に使われたデータについてしか対応していません。つまり、学習処理が行われたあとに出てきた未知の言葉や概念などは判断できません。これは適宜学習の再実行である程度は解決できる問題かもしれませんが、今のところユーザによる学習処理などはできないので、OpenAIの対応待ちとなってしまいます。
インターネットの利用が前提となる
当然のことながらOpenAIのAPIにアクセスできなければ、ChatGPTの機能を利用することはできません。インフラ面の制限からインターネットに繋ぐことが許可されていないプライベートネットワークや、IoTなどのエッジでの処理が必要である場合などで、ネットワークを利用できない場合には利用することができません。
速度が必ずしも速いわけではない
もちろん人手で同じことをするよりも、圧倒的な速度でレスポンスを返してくれますが、一般的なAPIと比較した場合に特段に速いわけではありません。これは汎化するために大規模なモデルになっているがゆえ仕方がないことではありますが、特化したモデルに比べれば速度面では遅いと言わざるを得ません。ただ、これはモデルの改善でよくなっていくものと思われます。実際に数ヶ月前に比べれば速度はかなり速くなっています。
ChatGPTの力を借りる
というわけで、ChatGPTはすべてを解決するというわけではないので、適宜使い所を見極めて使用していく必要があるかと思います。
今回であれば、ChatGPTの力を借りてアノテーションという人手で行っていた作業を自動化する試みを行いました。既存でも、学習したモデル自身にアノテーションされていないデータをアノテーションさせて、確信度が高くないデータだけ人にアノテーションさせようとするアプローチはありました。しかし、その判断を学習モデルに説明させること、特に普通の人が理解できる形で説明することは困難でした。ChatGPTであれば、モデル自身に人間の言葉でその理由を説明させることができます。
最後に
ChatGPTの性能には驚くばかりです。使い方によっては、今までは困難だったり、時間がかかっていた、たくさんのことを解決するポテンシャルを秘めていると感じます。
実際、今回のツール作成時にChatGPTで出力したコードを使ったり、いろいろ質問しつつ作成した部分もあります。専門家からすればChatGPTの出力には満足できない場合もあるかもしれませんが、ReactやAWS Chaliceを普段あまり使ったことがない自分のような人間が使う分には、大きな効率化につながりました。
ChatGPTはさまざまなテキストデータで学習されています。詳細は明かされていませんが、その中にはWebページや書籍などのデジタルデータが多数含まれています(参照)。
このため、ChatGPTは人類のデジタル領域における叡智の結晶と言っても過言ではないかと思います。ChatGPTを使ってどんな面白いサービスが出てくるか、ワクワクしますね!























 Peatix
Peatix Wantedly
Wantedly