
この記事はアピリッツの技術ブログ「DoRuby」から移行した記事です。情報が古い可能性がありますのでご注意ください。
こんにちは。
KBMJの佐藤です。
今回は Mechanize, Hpricot, MeCab でブログの頻出単語を調べてみます。
Mechanize について
Mechanize を使うと、ウェブサイトへのアクセスを自動化(リンクをたどる、フォームを submit する、リダイレクトをたどる、など)することができます。
Hpricot について
Hpricot は Ruby 用の HTML パーサです。HTML の解析や書き換えに威力を発揮するライブラリです。
MeCab について
MeCab はオープンソースの形態素解析エンジンです。
Mechanize のインストール
% sudo gem install mechanize
Hpricot のインストール
% sudo gem install hpricot
Mecab のインストール
% sudo port install mecab
% sudo port install mecab-ipadic-utf8
% sudo port install rb-mecab
コードを書く
require 'MeCab'
require 'rss'
require 'mechanize'
require 'kconv'
require 'hpricot'
require 'open-uri'
module MeCab
class Node
def category
return self.feature.split(/,/)[0]
end
def each(&b)
b[self]
self.next.each(&b) if self.next
end
end
end
agent = WWW::Mechanize.new
page = agent.get('http://d.hatena.ne.jp/akio0911/archive') # ページを開く
m = MeCab::Tagger.new
h={}
# エントリへのリンクを抽出
page.links_with(:href => /\/\d{8}\/p\d/).each{ |l|
puts l.href
doc = Hpricot(open(l.href))
text = doc.search("div.section").text.toutf8.gsub(/\t/, "").gsub(/\n/,"") # 文章部分を取得
nodes = m.parseToNode(text)
nodes.each do |node|
next unless node.category == '名詞' # 名詞以外はカウント対象としない
next if node.surface =~ /^\d+$/ # 数字も対象としない
if h[node.surface]
h[node.surface] += 1
else
h[node.surface] = 1
end
end
}
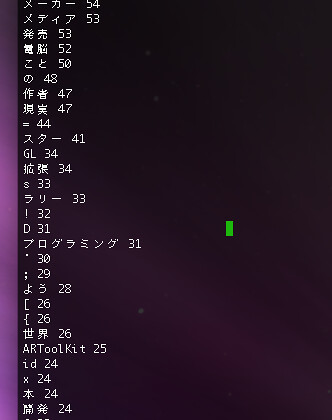
# カウント結果を出力
h.to_a.sort{ |a,b|
(b[1] <=> a[1]) * 2 + (a[0] <=> b[0])
}.each{ |e| puts "#{e[0]} #{e[1]}"}
さいごに
Mechanize, Hpricot, MeCab を使うと、ページ内容を解析するプログラムを簡単に書くことが出来ます。みなさんも是非試してみてはいかがでしょうか。
個人ブログ 拡張現実ライフ























 Peatix
Peatix Wantedly
Wantedly